Draw an Audio:将无声视频转换成包含日常音效的音频
Draw an Audio简介
Draw an Audio是由中国科学院自动化研究所和美团公司的研究团队共同开发的一种创新的视频到音频合成技术。该技术通过先进的遮罩注意力模块和时响度模块,能够根据视频内容自动生成与之匹配的音效,实现音频与视频在内容、时间和响度上的精准同步。它支持多指令输入,包括文本、绘制的遮罩和响度信号,使得音频生成过程更加灵活和可控。这项技术在电影制作、游戏开发、虚拟现实等领域具有广泛的应用前景,为提升视听体验提供了强大的技术支持。
Draw an Audio主要功能
- 视频到音频合成:将无声视频转换成包含日常音效的音频,增强视听体验。
- 多指令输入支持:通过文本、绘制的遮罩和响度信号等多种方式控制音频生成。
- 内容一致性保证:确保生成的音频与视频内容在语义上保持一致。
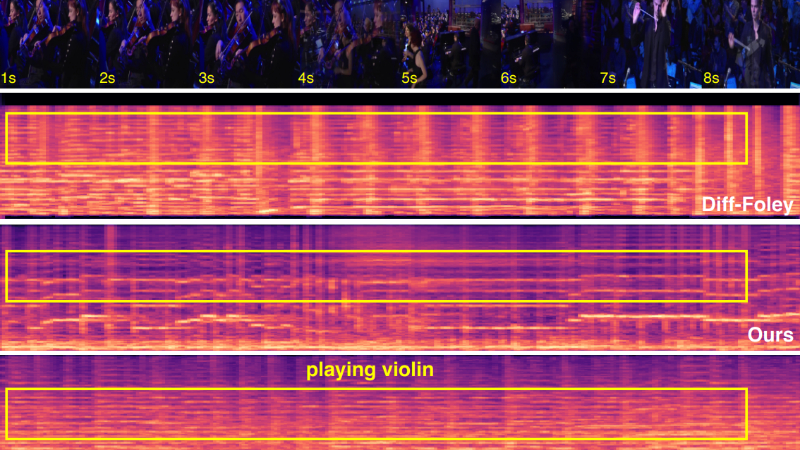
- 时间和响度同步:音频生成与视频的时间轴和响度变化相匹配。
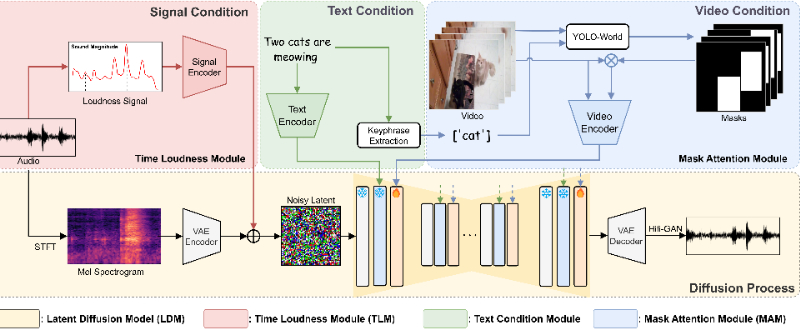
- 遮罩注意力模块(MAM):通过关注视频的特定区域来增强内容的相关性。
- 时响度模块(TLM):利用辅助响度信号确保音频的响度和时间与视频同步。
- 数据集扩展:通过添加字幕提示扩展VGGSound数据集,提高训练效果。
Draw an Audio技术原理
- 遮罩注意力模块(MAM):利用视频遮罩作为输入,使模型集中处理视频的特定部分,提升内容一致性。
- 时响度模块(TLM):引入手动画的响度信号,通过辅助信号控制生成音频的响度变化。
- Root Mean Square (RMS) 和 Exponentially Weighted Moving Average (EWMA):用于将原始音频转换成类似手工绘制的信号,作为TLM的输入。
- 变分自编码器(VAE):用于将音频特征压缩到一个潜在空间,减少计算负担。
- Latent Diffusion Model (LDM):作为基础模型,支持从潜在空间中生成音频。
- 双分类器自由引导(Dual Classifier-Free Guidance):在推理阶段,通过调节文本和视频条件的强度来生成音频。
- 多阶段混合音频合成:能够分阶段合成并混合多个音频,提供更广泛的实际应用。
- 大规模数据集训练:使用扩展的VGGSound-Caption数据集进行训练,提高模型的泛化能力。
Draw an Audio应用场景
- 电影和视频制作:在后期制作中,为视频添加逼真的音效,如脚步声、关门声等,以提升观众的沉浸感。
- 游戏开发:为游戏中的场景和对象生成匹配的音频效果,如武器射击声、环境背景声,增强游戏的真实性。
- 虚拟现实(VR):在VR体验中,根据视觉内容实时生成音频,提供更加丰富的感官体验。
- 教育和培训:在模拟训练软件中,根据视觉提示生成相应的音频,如模拟驾驶时的引擎声和环境声。
- 视频内容增强:为社交媒体上的视频内容自动添加音效,提高视频的吸引力和观看体验。
- 智能监控系统:在安全监控视频中,根据视觉识别结果生成音频提示,如检测到异常行为时发出警报声。
Draw an Audio项目入口
- 官方项目主页:https://yannqi.github.io/Draw-an-Audio/
- arXiv研究论文:https://arxiv.org/abs/2409.06135
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号