QA-MDT:中科大与科大讯飞联合开发的一款音乐生成模型
QA-MDT简介
QA-MDT(Quality-aware Masked Diffusion Transformer)是由中国科学技术大学与科大讯飞的联合研究团队开发的一种先进的音乐生成模型。该模型通过创新的质量感知训练策略,能够在训练过程中识别输入音乐波形的质量,从而生成高质量且多样化的音乐。QA-MDT利用掩蔽扩散变换器(MDT)的独特属性,有效提升了音乐的音频质量和音乐性,尤其在处理大规模数据集时,展现出卓越的性能,解决了音乐生成领域中长期存在的数据质量问题。

QA-MDT主要功能
- 高质量音乐生成:QA-MDT 能够根据文本描述生成高质量的音乐片段。
- 质量感知训练:模型在训练过程中能够识别并区分输入音乐波形的质量。
- 文本-音乐对齐:通过标题精炼数据处理方法,提高了文本描述与生成音乐之间的相关性。
- 多样化音乐输出:生成的音乐不仅质量高,而且风格多样,满足不同文本描述的要求。
QA-MDT技术原理
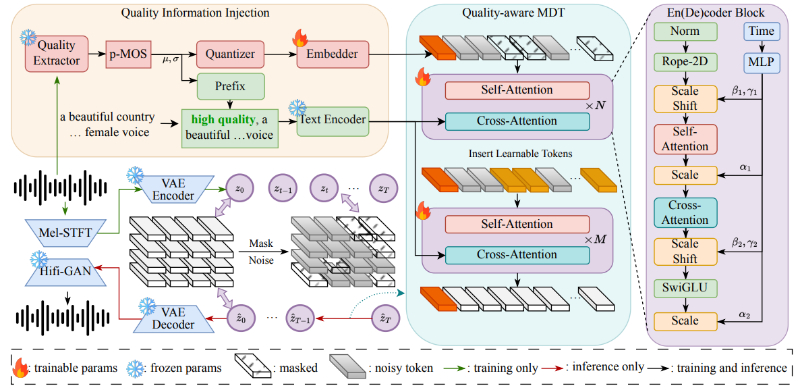
- 掩蔽扩散变换器(MDT):QA-MDT 使用 MDT 作为模型的主干,利用其在音乐信号的频谱空间中的有效建模能力。
- 质量感知训练策略:通过注入音乐伪 MOS(p-MOS)评分,模型能够在去噪阶段学习并区分音乐质量。
- 文本编码器与质量嵌入:文本描述通过编码器处理,并与量化的质量信息结合,以增强模型对音乐质量的控制。
- 精细化掩蔽策略:在训练阶段,通过变比的掩蔽策略,增强音乐频谱的空间相关性,加速模型的收敛。
- 音乐标题优化:使用大型语言模型(LLMs)和 CLAP 模型来同步音乐信号与标题,提高文本-音频的一致性。
- 生成过程的质量引导:在生成阶段,利用与高质量相关的信息引导模型生成音乐,确保音频的高质量输出。
- 客观和主观评价:通过客观指标(如 FAD、KL、IS)和主观评价(如 MOS)来评估生成音乐的质量和与文本的相关性。
QA-MDT应用场景
- 音乐制作:音乐制作人可以使用 QA-MDT 快速生成高质量的背景音乐或特定风格的音乐片段,提高创作效率。
- 多媒体内容生成:在视频制作、动画或游戏开发中,QA-MDT 可以根据场景的需要生成匹配的音乐,增强视听体验。
- 音乐教育:教育者可以利用 QA-MDT 来生成教学用的音乐示例,帮助学生理解不同音乐风格和构成。
- 音频内容平台:音乐流媒体服务或社交媒体平台可以利用 QA-MDT 为用户提供定制化的音乐推荐或生成用户个人的音乐作品。
- 虚拟助手和AI音乐创作:智能音箱或虚拟助手可以集成 QA-MDT,根据用户的情绪或环境生成相应的音乐,提供更加个性化的服务。
- 音乐治疗:在音乐治疗领域,QA-MDT 可以生成具有特定情绪或节奏特征的音乐,辅助治疗过程,提供放松或激励的效果。
QA-MDT项目入口
- GitHub代码库:https://github.com/QA-MDT
- arXiv技术论文:https://arxiv.org/pdf/2405.15863v2
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号