LLaMA-Omni:中国科学院推出的低延迟语音交互模型
LLaMA-Omni 简介
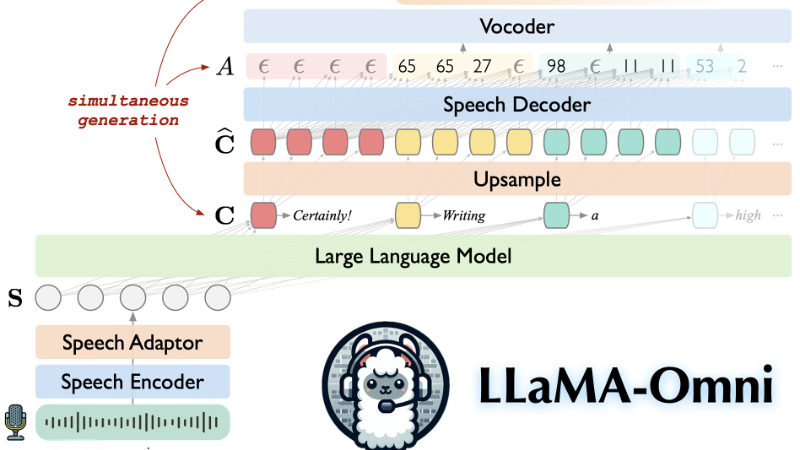
LLaMA-Omni是由中国科学院计算技术研究所智能信息处理重点实验室的团队开发的一种新型模型架构,旨在实现与大型语言模型(LLMs)的无缝语音交互。该模型通过集成预训练的语音编码器、语音适配器、LLM和流式语音解码器,能够在不将语音转录为文本的情况下,直接从语音指令生成文本和语音响应,显著降低了延迟并提升了用户体验。LLaMA-Omni的提出,代表了在开源社区构建基于LLMs的语音交互模型方面的重要探索。
LLaMA-Omni 主要功能
- 低延迟语音交互:能够以极低的延迟从语音指令中生成文本和语音响应。
- 无需语音转录:省去了将语音转换成文本的步骤,直接理解语音指令并作出回应。
- 高质量的响应生成:生成的文本和语音响应在内容和风格上都具有高质量。
- 高效的模型训练:在相对较少的计算资源下,训练过程快速,不到3天即可完成。
LLaMA-Omni 技术原理
- 语音编码器:使用Whisper-large-v3模型作为语音编码器,将用户的语音指令编码成有意义的表示形式。
- 语音适配器:通过一个可训练的适配器将语音表示适配到大型语言模型的嵌入空间,以便模型能够理解语音输入。
- 大型语言模型(LLM):采用Llama-3.1-8B-Instruct模型,它具备强大的推理能力,并与人类偏好良好对齐。
- 流式语音解码器:使用非自回归的流式Transformer模型,以流式方式生成与文本响应对应的离散单元序列。
- 连接时序分类(CTC):使用CTC技术来预测与语音响应对应的离散单元序列,实现非自回归的语音生成。
- 两阶段训练策略:
- 第一阶段:训练语音适配器和LLM直接从语音指令生成文本响应。
- 第二阶段:固定语音编码器、适配器和LLM,只训练语音解码器生成语音响应。
- 数据集构建:创建了InstructS2S-200K数据集,包含20万个语音指令及其对应的语音响应,以适应语音交互场景。
- 实时语音合成:在生成文本响应的同时,实时生成对应的语音输出,确保用户无需等待完整文本响应生成就能听到回复。
LLaMA-Omni 应用场景
- 智能助手:作为智能手机或智能家居设备的语音助手,提供即时语音指令响应。
- 客户服务:在客户服务领域,通过语音交互提供快速的查询回答和问题解决。
- 教育辅助:辅助语言学习,通过语音交互帮助学生练习发音和听力。
- 医疗咨询:在医疗咨询中提供实时语音交互,帮助解答病人的疑问。
- 会议记录:在会议中实时生成语音到文本的记录,并能通过语音指令检索信息。
- 车载系统:集成到车辆中,提供语音控制导航、音乐播放和通讯等功能。
LLaMA-Omni 项目入口
- GitHub代码库:https://github.com/ictnlp/LLaMA-Omni
- HuggingFace模型:https://huggingface.co/ICTNLP/Llama-3.1-8B-Omni
- arXiv技术论文:https://arxiv.org/pdf/2409.06666
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号