SafeEar简介
SafeEar是由浙江大学与清华大学联合开发团队提出的一种创新音频深度伪造检测框架。该框架能够在不侵犯语音内容隐私的前提下,有效识别出深度伪造的音频。通过先进的语音分离技术,SafeEar将语义信息与声学信息分离,仅利用声学信息进行深度伪造检测,从而避免了语义内容的暴露。此外,SafeEar还加入了现实世界中的编解码器增强,以提高检测的准确性和可靠性。通过在多个基准数据集上的广泛实验,SafeEar展现了其卓越的检测性能和对多语言内容隐私的强效保护。
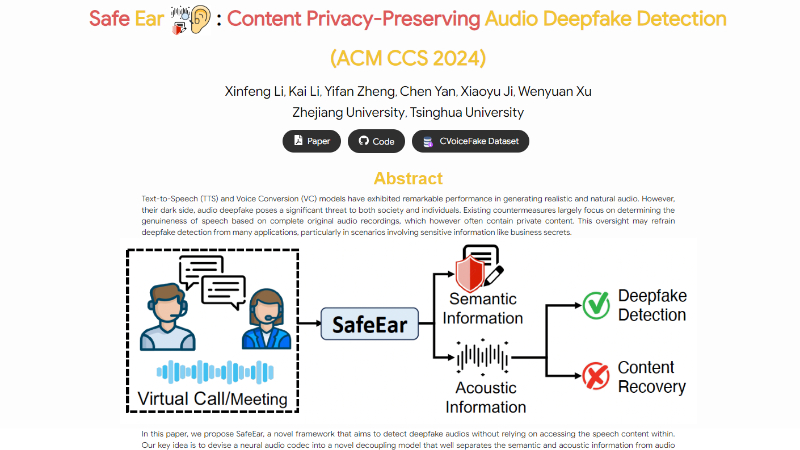
SafeEar主要功能
- 深度伪造音频检测:能够识别出由TTS和VC技术生成的深度伪造音频。
- 隐私保护:在检测过程中保护语音的语义内容不被泄露。
- 多语言处理:能够处理并保护多种语言的语音内容。
- 抵抗编解码器变化:即使在音频传输过程中经过编解码器处理,也能保持检测准确性。
SafeEar技术原理
- 语音分离:
- 利用神经音频编解码器将语音信号分解成语义和声学信息。
- 通过设计一个特殊的解耦模型(Codec-based Decoupling Model, CDM),实现语义和声学信息的分离。
- 声学信息处理:
- 提取声学信息(如韵律和音色)用于深度伪造检测。
- 应用随机洗牌算法增加声学信息的保密性。
- 深度伪造检测器:
- 开发基于Transformer的检测器,专注于处理声学信息。
- 利用多头自注意力(MHSA)机制优化检测器的性能。
- 现实世界编解码增强:
- 在训练过程中整合多种代表性编解码器,如OPUS和G.722。
- 通过模拟真实世界的音频传输环境,增强模型的泛化能力。
- 抗内容恢复:
- 通过声学信息的洗牌和压缩,防止语义内容被机器或人类听觉分析恢复。
- 实验证明,SafeEar能有效抵抗不同级别的内容恢复攻击。
- 多语言支持:
- 通过跨语言的解耦能力,SafeEar能够处理和保护不同语言的语音内容。
- 基准测试构建:
- 构建了包括多个数据集的全面基准,用于评估深度伪造检测和内容隐私保护性能。
SafeEar应用场景
- 社交媒体平台:检测和防止在社交媒体上传播的深度伪造音频,保护公众免受误导。
- 金融交易验证:在电话交易或身份验证过程中,确保交易请求的真实性,防止通过深度伪造音频进行欺诈。
- 法律和合规:在法律调查和取证过程中,检测录音证据是否经过篡改,确保证据的有效性。
- 政府和公共安全:帮助政府机构检测和阻止可能用于政治宣传或虚假信息传播的深度伪造音频。
- 企业通信安全:在企业的电话会议和通信中确保语音信息的真实性,保护商业秘密和敏感信息。
- 个人隐私保护:允许个人在进行网络通话或使用语音助手时,确保他们的语音数据不被滥用或未经授权的分析。
SafeEar项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号