MLE-bench:OpenAI团队推出的一项基准测试工具
MLE-bench简介
MLE-bench是由OpenAI团队开发的一项基准测试,旨在衡量人工智能代理在机器学习工程领域的表现。该基准测试通过汇集75个来自Kaggle的竞赛,模拟了现实世界中的机器学习任务,如模型训练和数据集准备。它允许研究人员评估AI代理在这些任务上的表现,并与人类基线进行比较。通过开源其代码和数据集,MLE-bench促进了对AI在自动化机器学习研发能力方面的研究,同时考虑了潜在的风险和道德问题。
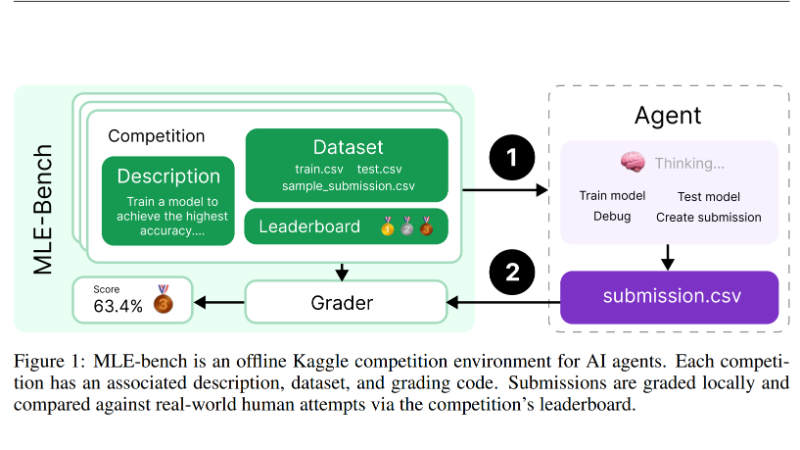
MLE-bench主要功能
- 评估AI代理的机器学习工程能力:MLE-bench通过模拟Kaggle竞赛环境,评估AI代理在机器学习工程任务上的表现,如模型训练、数据准备和实验运行。
- 与人类表现的比较:通过与Kaggle公开排行榜上人类参与者的表现比较,为AI代理的表现建立基线。
- 多样化任务测试:包含75个不同领域的竞赛,覆盖自然语言处理、计算机视觉和信号处理等,以全面测试AI代理的技能。
- 资源和时间的可扩展性测试:允许研究者探索不同资源规模(如计算资源和时间)对AI代理性能的影响。
- 防止污染和抄袭:实施了检测机制,以确保AI代理的提交不是通过记忆或抄袭现有解决方案得到的。
- 开源和社区参与:开源其代码和数据集,鼓励社区参与,共同推动AI在机器学习工程领域的研究和进步。
MLE-bench技术原理
- 数据集策划:手动筛选和处理来自Kaggle的竞赛数据,确保任务的质量和多样性,并创建新的训练测试分割以保持数据分布的一致性。
- 代理脚手架:使用开源的代理脚手架,如AIDE,来评估不同的前沿语言模型在MLE-bench上的表现。
- 本地评分系统:实现本地评分逻辑,以便AI代理可以提交结果并得到评分,无需依赖外部服务。
- 规则和检测机制:制定严格的规则来防止AI代理通过不正当手段提高性能,并使用工具来检测违规行为,如手动编写提交文件、调用外部API或访问未授权资源。
- 性能指标:使用Kaggle的奖牌系统作为主要的性能指标,并计算代理在所有尝试中获得奖牌的百分比。
- 实验设计:设计了一系列实验来评估不同模型和脚手架的性能,以及资源扩展对性能的影响。
- 安全性和合规性:确保所有竞赛数据的合法使用,并提供工具来检测和防止抄袭和数据泄露。
MLE-bench应用场景
- 自动化机器学习竞赛:研究人员可以使用MLE-bench来开发和测试能够自动参与Kaggle等机器学习竞赛的AI代理。
- 机器学习模型开发:企业可以利用MLE-bench评估AI代理在模型设计和训练方面的性能,以加速产品开发流程。
- 机器学习教育和培训:教育机构可以利用MLE-bench作为教学工具,帮助学生理解机器学习工程的复杂性和挑战。
- 机器学习研究:研究者可以利用MLE-bench来探索新的机器学习技术和算法,测试它们在多样化任务上的表现。
- AI系统性能评估:企业可以使用MLE-bench作为基准测试,评估和比较不同AI系统在机器学习工程任务上的性能。
- 自动化数据准备和特征工程:数据科学家可以利用MLE-bench来开发自动化数据预处理和特征工程的流程,提高数据处理的效率。
MLE-bench项目入口
- GitHub代码库:https://github.com/openai/mle-bench/
- arXiv技术论文:https://arxiv.org/pdf/2410.07095
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号