MM1.5简介
MM1.5是苹果公司推出的多模态大型语言模型,旨在提升模型在文本丰富的图像理解、视觉指代和定位以及多图像推理方面的能力。该模型包括不同规模的版本,从1B到30B参数,并引入了专为视频理解和移动UI理解设计的变体。MM1.5通过采用数据为中心的训练方法,在模型训练的整个生命周期中系统地探索了不同数据混合的影响,以实现在小规模模型上也能有出色的表现。此外,MM1.5还通过大量的实证研究提供了对训练过程和决策的深入见解,为未来MLLMs的发展提供了宝贵的指导。
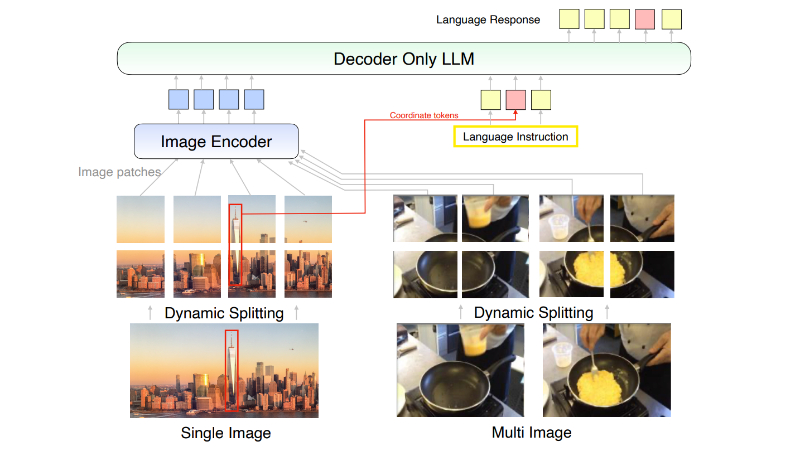
MM1.5主要功能
- 文本丰富的图像理解:MM1.5能够理解包含丰富文本的图像,支持任意图像宽高比和高达4百万像素的分辨率。
- 视觉指代和定位:模型能够解释视觉提示,如点和边界框,并能够通过图像边界框生成基于文本输出的定位响应。
- 多图像推理和上下文学习:通过大规模交错预训练,MM1.5具备强大的上下文学习和多图像推理能力。
- 视频理解:MM1.5-Video变体专为视频理解设计,能够处理视频数据并生成响应。
- 移动UI理解:MM1.5-UI变体专注于移动用户界面的理解,能够在移动设备屏幕上进行视觉指代和定位。
MM1.5技术原理
- 数据为中心的训练方法:MM1.5在模型训练的整个生命周期中,系统地探索不同数据混合的影响,包括高质量的OCR数据和合成字幕。
- 持续预训练:在监督微调之前,引入了一个额外的高分辨率持续预训练阶段,以增强文本丰富的图像理解性能。
- 监督微调(SFT):通过优化视觉指令调整数据的混合比例,进行监督微调,以提升模型在特定任务上的性能。
- 动态高分辨率处理:采用动态图像分割方法,根据图像的分辨率和宽高比动态地将图像分割为子图像,以提高高分辨率图像编码的效果。
- 混合专家(MoE)模型:在某些变体中,MM1.5使用混合专家系统来增强性能,同时在推理过程中保持激活参数数量的恒定。
- 大规模预训练:通过大规模预训练,MM1.5能够在零样本和少样本学习场景中展现出色的能力。
- 优化的视觉编码器:使用CLIP图像编码器和LLM主干,以及C-Abstractor作为视觉-语言连接器,以支持复杂的视觉和语言任务。
-
详细的实证研究:通过大量的消融实验,MM1.5提供了对训练过程和决策的深入见解,以指导未来的研究和模型开发。
MM1.5应用场景
- 图像内容分析:MM1.5能够理解图像中的文本信息,适用于自动化图像内容分析,如广告牌、菜单或产品包装上的文本识别。
- 视觉搜索引擎:利用其视觉指代和定位能力,MM1.5可以用于图像搜索应用,帮助用户通过描述找到特定图像。
- 辅助驾驶系统:在自动驾驶领域,MM1.5能够理解道路标志和交通信号,为驾驶决策提供支持。
- 智能客服:结合图像和文本理解能力,MM1.5可以作为智能客服,通过分析用户上传的图片来提供针对性的帮助。
- 教育和培训:MM1.5能够处理教育内容中的图像和文本,用于开发互动式学习材料和教育工具。
-
医疗图像分析:在医疗领域,MM1.5可以帮助分析医学影像,如X光片、CT扫描或MRI图像,辅助医生进行诊断。
MM1.5项目入口
- arXiv技术论文:https://arxiv.org/pdf/2409.20566v1
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号