SPIRIT-LM简介
SPIRIT-LM是由Meta AI团队开发的一种创新的多模态语言模型,它能够无缝地混合和理解文本与语音数据。该模型通过在大量文本和语音单位上进行连续预训练,实现了对两种模态的深入理解,并能够灵活地在文本和语音之间进行转换。SPIRIT-LM包含基础版和表达性版,后者额外考虑了音高和风格,以捕捉语音中的情感表达。这一模型不仅在语义理解上表现出色,还具备跨模态任务的少样本学习能力,为构建更自然、更具表现力的语音交互系统提供了新的可能性。
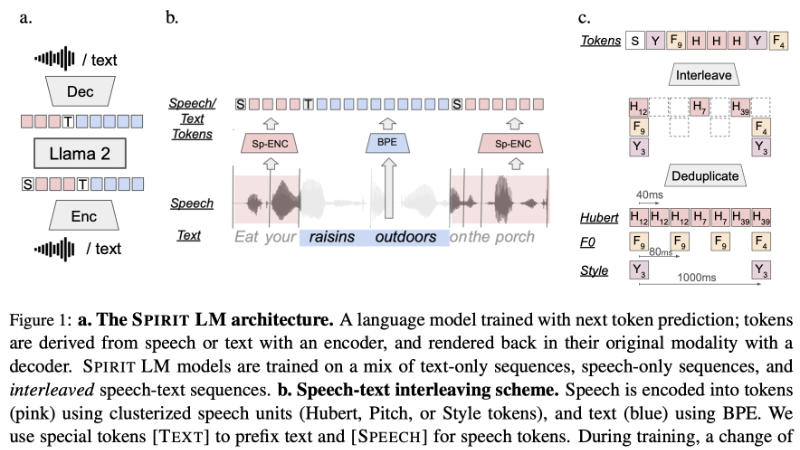
SPIRIT-LM主要功能
- 跨模态理解与生成: SPIRIT-LM能够理解和生成文本和语音,实现两种模态之间的无缝转换。
- 少样本学习: 模型能够在少量示例的指导下快速学习并执行特定的任务,如自动语音识别(ASR)和文本到语音(TTS)。
- 情感和表达性建模: 表达性版本(SPIRIT-LM-EXPRESSIVE)通过模拟音高和风格单元,能够捕捉和生成具有情感表达的语音。
- 多模态任务执行: 模型能够处理涉及文本和语音的复杂任务,如情感保持、语音分类等。
- 连续预训练: 基于预训练的文本语言模型,通过持续训练扩展到语音模态,增强了模型的多模态能力。
SPIRIT-LM技术原理
- 词级交错训练: 将语音和文本序列在词级上交错,使得模型能够在训练中同时处理两种模态的数据。
- HuBERT模型: 使用HuBERT(Hidden Unit BERT)模型作为语音编码器,将语音信号转换为离散的语义单元。
- 子词BPE编码: 文本通过子词Byte Pair Encoding(BPE)进行编码,以提高模型对词汇的覆盖和处理能力。
- 模态标记: 在输入序列中使用特殊的模态标记(如[TEXT]和[SPEECH])来指示模型处理的是文本还是语音数据。
- 多阶段训练: 模型首先在文本数据上进行预训练,然后通过加入语音数据进行持续训练,以实现跨模态学习。
- 表达性单元: 在SPIRIT-LM-EXPRESSIVE版本中,除了语义单元外,还加入了音高和风格单元,以增强模型对语音情感的捕捉和表达能力。
- 少样本提示: 利用少量示例(prompting)来引导模型执行特定任务,展示了模型的灵活性和适应性。
SPIRIT-LM应用场景
- 智能助手: SPIRIT-LM可以作为智能助手的核心,理解用户的语音指令并提供书面回复,或将书面指令转换为语音输出,提升人机交互的自然性和便捷性。
- 语音翻译: 在跨语言交流中,模型可以将一种语言的语音实时翻译成另一种语言的语音或文本,促进不同语言背景用户之间的沟通。
- 自动字幕生成: 对于视频内容创作者来说,SPIRIT-LM能够自动将语音内容转换成文本字幕,提高内容的可访问性和国际化传播。
- 情感分析: 在客户服务领域,模型能够分析语音中的情感倾向,帮助企业更好地理解客户反馈,提升服务质量。
- 语音内容创作: 对于需要生成富有表现力语音内容的应用,如有声书或虚拟角色配音,SPIRIT-LM能够创作出具有情感色彩的语音,增强用户体验。
- 教育辅助: 在语言学习应用中,SPIRIT-LM可以提供语音识别和发音纠正功能,帮助学习者提高发音准确性,同时提供书面材料以加深理解。
SPIRIT-LM项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号