PaddleOCR 2.9:百度飞桨推出的开源光学字符识别(OCR)工具包
PaddleOCR 2.9简介
PaddleOCR 2.9是由百度飞桨(PaddlePaddle)推出的一款开源光学字符识别(OCR)工具包。该版本引入了多项新特性,包括直接保存OCR输出结果、增强的数据预处理选项以及对GPU、XPU和NPU设备的支持,提升了处理速度和准确性。此外,PaddleOCR 2.9还新增了芬兰语字典文件,扩展了多语言支持,增强了系统的实用性和灵活性。通过改进的容错机制,单个损坏图像不会影响批处理的推理过程,使得用户在进行文本识别时更加高效和可靠。
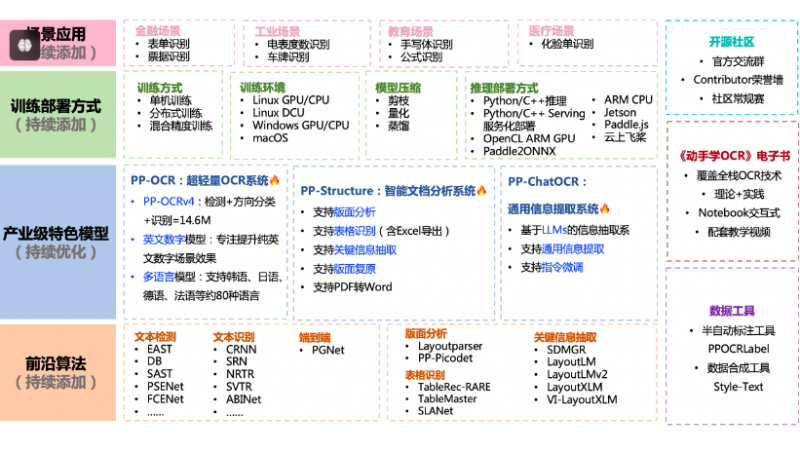
PaddleOCR 2.9主要功能
- 文本检测与识别:能够识别多种语言的文本,支持多种字体和样式。
- 表格与结构化数据提取:从文档中提取表格数据,方便后续分析。
- 图像预处理:提供多种图像预处理方法,如去噪、增强等,以提高识别准确性。
- 多语言支持:支持包括中文、英文、法文、德文等在内的多种语言,适应国际化需求。
- 模型训练与微调:用户可以根据自己的数据集进行模型训练或微调,以满足特定应用场景。
PaddleOCR 2.9技术原理
- 图像输入与预处理:用户将待识别的图像输入系统,随后进行图像矫正和增强,以提高图像质量,确保后续识别的准确性。
- 文本检测:使用深度学习模型(如DB、EAST等)检测图像中的文本区域。这一阶段通过卷积神经网络(CNN)提取特征,识别出文本的位置和大小。
- 特征提取与序列识别:通过深层双向LSTM网络对检测到的文本区域进行特征提取,并使用Connectionist Temporal Classification (CTC)方法解决字符对齐问题,从而实现对图像中文字的准确识别。
- 表格与结构化数据解析:针对包含表格的文档,PaddleOCR使用专门的模型识别和解析表格结构,提取其中的数据。
- 结果输出:系统将识别结果(包括识别出的文本及其置信度)返回给用户,支持进一步的数据处理和应用。
PaddleOCR 2.9应用场景
- 教育行业:用于识别教科书、试卷等文档,辅助数字化学习资源。
- 医疗行业:提取病历、处方等信息,提高医疗记录管理效率。
- 金融行业:自动化处理发票、账单等文档,提升财务管理效率。
- 零售与电商:扫描商品标签和条形码,加速库存管理和订单处理。
- 法律行业:数字化法律文书,方便检索和存档,提高工作效率。
PaddleOCR 2.9项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号