TIME-MOE简介
TIME-MOE是一种创新的大规模时间序列预测模型,采用混合专家(MoE)架构,通过激活模型中只有一部分网络来提高计算效率,同时保持模型的高容量。它由仅解码器的Transformer模型组成,支持自回归方式和灵活的预测范围。TIME-MOE在新引入的Time-300B数据集上预训练,该数据集覆盖9个领域,包含超过3000亿个时间点。模型首次扩展到24亿参数,显著提高了预测精度,成为处理真实世界时间序列预测挑战的先进解决方案。
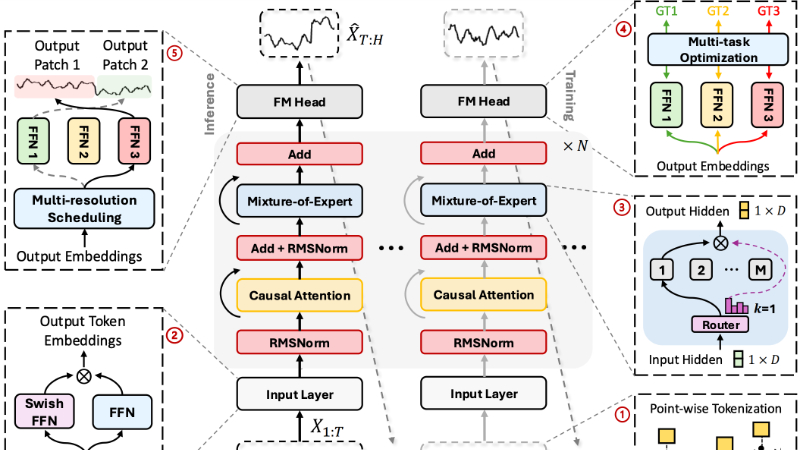
TIME-MOE主要功能
- 大规模时间序列预测: TIME-MOE能够处理大规模时间序列数据,并提供准确的未来值预测。
- 灵活的预测范围: 支持不同长度的预测范围,使其适用于多种实际应用场景。
- 自回归预测方式: 模型以自回归方式运行,能够根据历史数据预测未来的时间点。
- 多分辨率预测: 引入多分辨率预测头,允许同时进行不同时间尺度的预测。
- 稀疏激活设计: 通过混合专家(MoE)架构,模型在预测时只激活一部分网络,提高计算效率。
- 多任务学习优化: 在训练时,模型针对多个预测分辨率进行优化,提升模型的泛化能力。
TIME-MOE技术原理
- 混合专家(MoE)架构: TIME-MOE利用MoE设计,将输入动态路由到不同的专家子网络,每个专家处理特定的数据模式。
- 点式令牌化: 时间序列数据被点式令牌化,以确保时间信息的完整性,并增强模型处理变长序列的能力。
- 自回归机制: 模型通过自回归方式进行预测,可以逐点生成未来的时间序列。
- 多分辨率预测头: 设计了多个输出投影,每个对应不同的预测范围,允许模型在训练时就考虑不同时间尺度的预测。
- 高效的计算模式: 通过激活模型中只有一部分网络来减少每次预测的计算负担,实现计算资源的有效利用。
- 预训练和微调: 模型在大规模的时间序列数据集Time-300B上进行预训练,并通过微调适应特定的下游任务。
- 损失函数优化: 使用Huber损失函数提高对异常值的鲁棒性,并采用辅助损失来平衡专家层的负载,避免路由崩溃问题。
TIME-MOE应用场景
- 能源消耗预测: TIME-MOE能够预测家庭、建筑或电网的能源使用情况,帮助优化能源分配和管理。
- 金融市场分析: 在金融领域,该模型可用于预测股票价格、交易量等,辅助投资决策和风险管理。
- 气候和天气预测: 利用TIME-MOE预测气温、降水等气象变量,以改善天气预报的准确性和应对气候变化。
- 医疗健康分析: 在医疗领域,模型可以预测疾病的传播趋势、住院需求等,助力公共卫生资源的规划。
- 交通流量优化: 通过预测交通流量和拥堵情况,TIME-MOE有助于交通管理和城市交通规划,减少拥堵。
- 销售和需求预测: 在零售业中,模型能够预测产品的销售趋势和消费者需求,帮助库存管理和供应链优化。
TIME-MOE项目入口
- GitHub代码库:https://github.com/Time-MoE/Time-MoE
- HuggingFace模型库:https://huggingface.co/datasets/Maple728/Time-300B
- arXiv技术论文:https://arxiv.org/pdf/2409.16040
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号