DuoAttention:提高LLMs在处理长文本上下文时的推理效率
DuoAttention简介
DuoAttention是由麻省理工学院(MIT)的研究团队开发的一种新型框架,旨在提高大型语言模型在处理长文本上下文时的推理效率。该框架通过区分关键的“检索头”和主要关注近期信息的“流式头”,优化了模型的内存使用和计算资源。DuoAttention能够在不牺牲长文本处理能力的前提下,显著减少模型的解码和预填充内存及延迟,使得在单个GPU上处理数百万token的上下文成为可能。这一创新为长文本应用中的LLM部署提供了有效的解决方案。
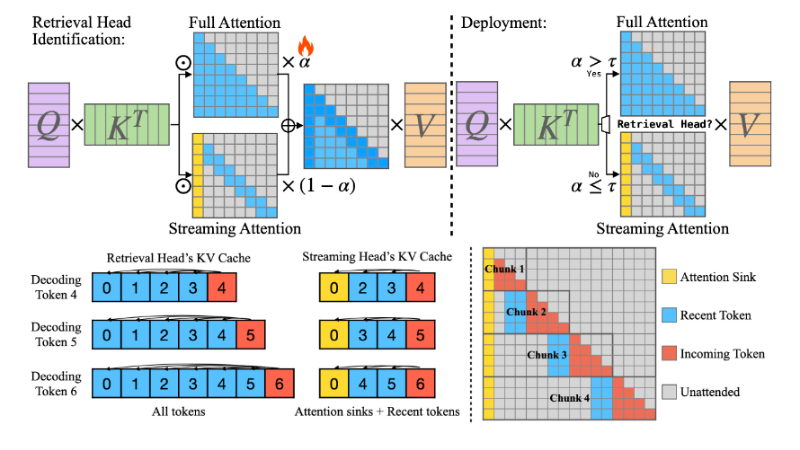
DuoAttention主要功能
- 检索头和流式头的区分:识别并区分大型语言模型中的检索头(Retrieval Heads)和流式头(Streaming Heads)。
- 内存和计算资源优化:通过为检索头应用全KV缓存,而为流式头应用轻量级、固定长度的KV缓存,减少模型在解码和预填充过程中的内存使用和延迟。
- 长文本处理能力保持:确保在减少内存和计算资源消耗的同时,不损失处理长文本上下文的能力。
- 解码和预填充加速:提升模型解码速度和预填充效率,显著减少处理长文本时的延迟。
- 与量化技术兼容:与模型权重和KV缓存的量化技术兼容,进一步提升模型在有限内存中的处理能力。
DuoAttention技术原理
- 检索头识别:使用基于优化的方法和合成数据集来准确识别需要完整注意力机制的检索头。
- 注意力头的二分:将注意力头分为检索头和流式头,基于它们的功能和对长文本上下文的依赖程度。
- 动态KV缓存管理:根据识别结果,为检索头和流式头动态分配不同大小的KV缓存,优化内存使用。
- 块稀疏近似:对于流式头,使用块稀疏近似来实现对Λ-like注意力掩码的高效计算。
- 合成数据集设计:设计合成数据集,通过嵌入特定序列(如“通过检索密钥”)来训练模型,确保在压缩KV缓存的同时保持模型性能。
- 优化和正则化:在训练过程中,使用L2差异作为蒸馏损失,并结合L1正则化项来鼓励门控值的稀疏性。
- 快速推理:在推理时,通过二值化注意力策略来快速区分检索头和流式头,实现快速的注意力计算。
- 批处理优化:设计兼容批处理的操作,以提高在大规模批处理场景中的效率。
DuoAttention应用场景
- 长文本内容理解:DuoAttention可以处理大量的文本数据,适用于需要分析和理解长篇文档的场景,如法律文件、科学论文和历史文献的分析。
- 多轮对话系统:在聊天机器人或虚拟助手中,DuoAttention能够维持长对话上下文,使对话更加连贯和个性化。
- 长篇内容摘要:对于需要生成长文章或书籍摘要的应用,DuoAttention能够捕捉关键信息并生成准确的摘要。
- 视觉语言模型:DuoAttention可以与视觉语言模型结合,处理和理解包含大量视觉和文本信息的视频内容。
- 教育和研究:在教育领域,DuoAttention可以帮助分析学生的学习历史和行为模式,为个性化教学提供支持;在研究中,它能够处理和分析大规模的科研数据。
- 企业知识管理:DuoAttention可以用于企业内部的知识库建设,帮助员工快速检索和获取公司历史文档、案例研究和内部通讯记录。
DuoAttention项目入口
- GitHub代码库:https://github.com/mit-han-lab/duo-attention
- arXiv技术论文:https://arxiv.org/pdf/2410.10819
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号