ROCKET-1:提升视觉语言模型在开放世界环境中的交互能力
ROCKET-1简介
ROCKET-1是一个由北京大学、加州大学洛杉矶分校和BIGAI团队共同开发的先进低层次策略模型,旨在通过视觉-时间上下文提示协议,提升视觉语言模型在开放世界环境中的交互能力。该模型能够实时预测动作,基于连续的视觉观察和对象分割掩码,有效解决需要复杂空间理解的任务。ROCKET-1通过整合先进的视频分割模型SAM-2,增强了对象跟踪能力,并在Minecraft等环境中展示了其卓越的性能,特别是在执行创造性和复杂任务时,展现了零样本泛化的能力。这一突破性技术为多模态人工智能在实际应用中的决策制定和问题解决开辟了新的可能性。
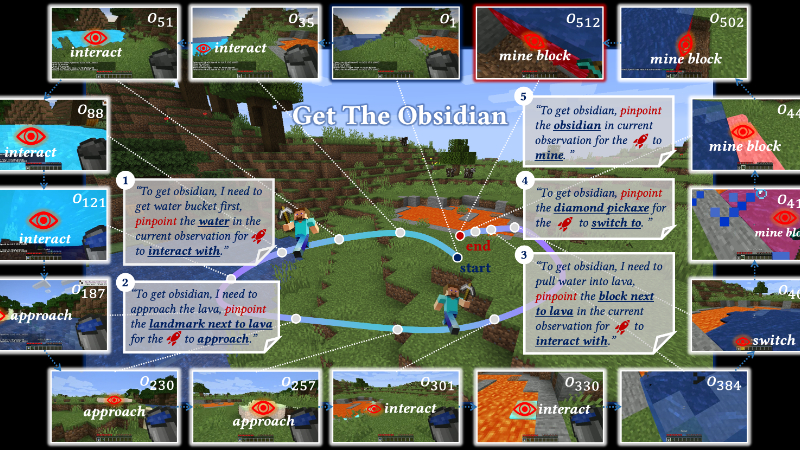
ROCKET-1主要功能
- 复杂任务解决能力:ROCKET-1能够处理需要复杂空间理解和创造性思维的复杂任务。
- 实时动作预测:基于视觉观察和对象分割掩码,ROCKET-1能够实时预测并执行动作。
- 视觉-时间上下文提示:利用过去和现在的观察中的对象分割来指导与环境的交互。
- 层次化代理架构:与高级别推理模型协同工作,将复杂任务分解为可执行的子任务。
- 零样本泛化:在未见过的任务上展示出强大的零样本泛化能力。
ROCKET-1技术原理
- 视觉-时间上下文提示协议:通过对象分割来强调过去和当前视觉观察中的感兴趣区域,并传达交互类型提示。
- 因果变换器(Causal Transformer):使用变换器模型来捕捉观察之间的依赖关系,这对于部分可观察环境中的任务表示至关重要。
- 对象分割与跟踪:集成SAM-2模型,实现对对象的实时分割和跟踪,增强了模型在部分可观察环境中的性能。
- 行为克隆损失优化:通过行为克隆损失进行优化,直接学习条件策略,而无需依赖于奖励信号。
- 向后轨迹重标注方法:使用SAM-2以反向时间顺序自动检测和分割所需对象,以生成用于训练ROCKET-1的训练数据集。
- 层次化代理结构:结合了GPT-4o、Molmo、SAM-2和ROCKET-1,利用VLMs的视觉语言推理能力来分解任务,并确定基于环境观察的对象交互。
- 数据融合与注意力池化:将观察和对象分割像素级连接,并通过视觉背板进行深度融合,然后使用注意力池化层进行处理。
- 随机丢弃机制:在训练过程中随机丢弃分割信息,迫使模型从过去输入中推断用户意图,增强模型的时间推理能力。
ROCKET-1应用场景
- 游戏环境交互:在Minecraft等沙盒游戏中,ROCKET-1可以控制游戏内角色执行复杂的建造和探索任务。
- 机器人导航:在现实世界的机器人应用中,ROCKET-1可以帮助机器人理解和执行基于视觉的空间任务,如避开障碍物或导航至特定位置。
- 增强现实辅助:在增强现实(AR)中,ROCKET-1能够识别和与现实世界中的对象交互,为用户提供实时的虚拟信息和辅助。
- 自动驾驶模拟:在自动驾驶车辆的模拟训练中,ROCKET-1可以模拟车辆对周围环境的理解和响应,提高模拟的真实性。
- 工业自动化:在工业自动化领域,ROCKET-1可以指导机器人进行精确的物体操作和装配工作,提高生产效率和安全性。
- 智能监控系统:ROCKET-1可以集成到视频监控系统中,实时分析和响应监控画面中的异常事件,如入侵检测或紧急情况响应。
ROCKET-1项目入口
- 官方项目主页:https://craftjarvis.github.io/ROCKET-1/
- GitHub源码库:https://github.com/CraftJarvis/ROCKET-1
- arXiv研究论文:https://arxiv.org/pdf/2410.17856
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号