MimicTalk:生成个性化和富有表现力的3D说话人脸视频
MimicTalk简介
MimicTalk是由浙江大学与字节跳动的联合研究团队开发的一种创新技术,它能够在短短15分钟内生成个性化和富有表现力的3D说话人脸视频。这项技术通过利用基于神经辐射场(NeRF)的泛化模型,结合静态-动态混合适应流程和上下文风格化的音频到运动模型,实现了对目标身份的静态外观和动态特征的快速学习与模仿,显著提高了视频质量、效率和表现力,超越了以往的个性化说话人脸生成方法。
MimicTalk主要功能
- 个性化3D说话人脸生成:MimicTalk能够根据特定个体的面部特征和说话风格,快速生成逼真的3D说话视频。
- 静态和动态特征学习:通过静态-动态混合适应流程,模型可以学习并模仿目标个体的静态外观(如面部几何形状和纹理)和动态特征(如说话时的面部运动)。
- 上下文风格化音频到运动模型:MimicTalk采用了一种音频到运动的模型,能够根据参考视频中的说话风格生成个性化的面部运动。
- 快速适应新身份:利用预训练的泛化模型,MimicTalk可以在极短的时间内适应新的身份,相比传统方法大幅提高了效率。
- 高表现力视频生成:通过模仿参考视频中的说话风格,MimicTalk能够生成具有高度表现力的说话视频。
MimicTalk技术原理
- 神经辐射场(NeRF):MimicTalk基于NeRF构建,这是一种用于存储和渲染复杂场景和对象的深度学习技术,能够隐式地学习目标身份的静态和动态信息。
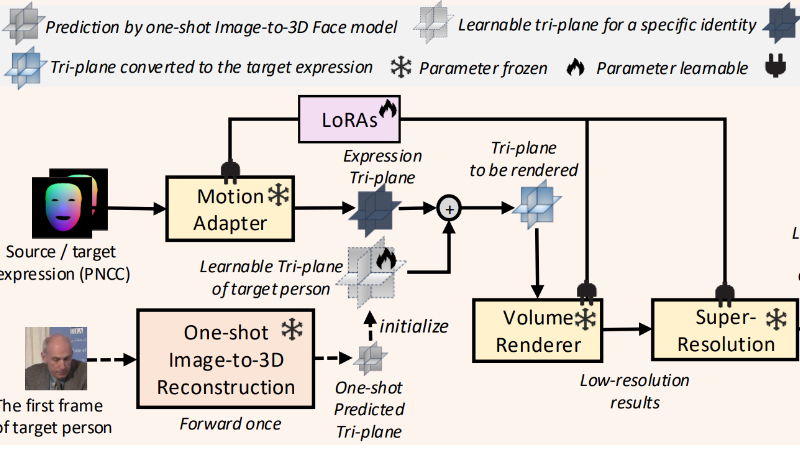
- 静态-动态混合适应流程(SD-Hybrid Adaptation):通过优化预训练的3D人脸表示和注入低秩适应(LoRAs)来学习目标个体的静态和动态特征。
- 低秩适应(Low-Rank Adaptation, LoRA):一种高效的模型适应技术,通过在模型的每个线性层中注入低秩可学习矩阵来实现对目标个体特征的快速学习。
- 上下文风格化音频到运动(In-Context Stylized Audio-to-Motion, ICS-A2M)模型:利用流匹配(Flow Matching)技术,结合音频条件和风格提示,生成与音频同步且具有目标说话风格的面部运动。
- 流匹配(Flow Matching):一种生成模型,用于预测数据点在连续时间步上的速度场,从而将数据点从简单先验分布推向目标分布。
- 分类器自由引导(Classifier-Free Guidance, CFG):一种在采样过程中操纵条件强度的技术,用于增强风格模仿质量,通过混合有无风格提示的网络预测来构建CFG速度场。
MimicTalk应用场景
- 视频会议:在远程工作中,MimicTalk可以生成逼真的3D头像,提升线上会议的互动性和真实感。
- 虚拟主播:在新闻播报或娱乐直播中,使用MimicTalk技术创建虚拟形象,以吸引观众并提供新颖体验。
- 在线教育:教师可以使用MimicTalk生成的个性化3D形象进行远程教学,使课程更加生动有趣。
- 客户服务:在虚拟客服系统中,MimicTalk可以生成逼真的客服代表形象,提供更加亲切和专业的服务。
- 游戏和娱乐:在游戏或虚拟现实应用中,MimicTalk技术可以用来创建具有高度表现力和个性化的虚拟角色。
- 电影和动画制作:在影视制作中,MimicTalk可以用于生成或增强角色的面部表情和动作,减少传统动作捕捉的需求。
MimicTalk项目入口
- 项目主页:https://mimictalk.github.io/
- GitHub代码库:https://github.com/yerfor/MimicTalk
- arXiv技术论文:https://arxiv.org/pdf/2410.06734
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号