EchoMimicV2:能够生成与音频内容高度一致的高质量动画视频
EchoMimicV2简介
EchoMimicV2是由阿里蚂蚁集团推出的一种创新的半身人体动画生成技术。该技术通过结合参考图像、音频剪辑和手部姿势序列,能够生成与音频内容高度一致的高质量动画视频。通过采用Audio-Pose Dynamic Harmonization策略和Phase-specific Denoising Loss,EchoMimicV2在简化动画生成条件的同时,提升了动画的细节表现力和动作质量,成为推动半身人体动画技术发展的重要进步。
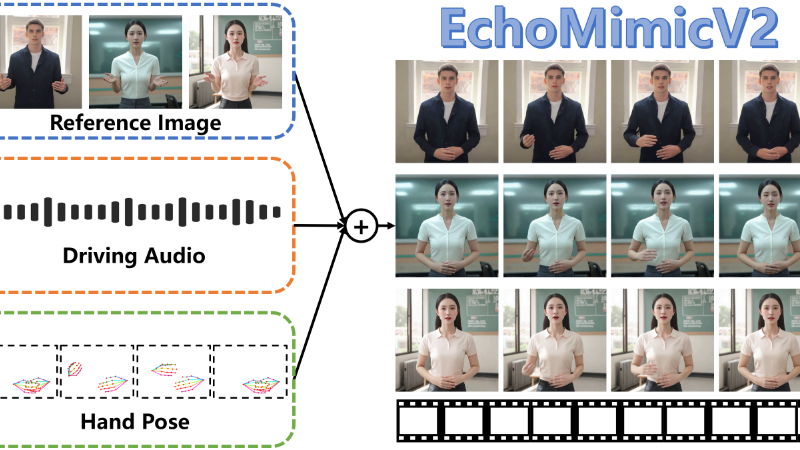
EchoMimicV2主要功能
- 高质量动画视频生成:EchoMimicV2能够利用参考图像、音频剪辑和手部姿势序列生成高质量的半身人体动画视频。
- 音频与动作同步:确保生成的动画视频中的动作与音频内容在语义、情感和节奏上保持一致。
- 简化动画生成条件:通过减少不必要的条件和复杂的条件注入模块,简化了动画生成过程。
- 数据增强:使用Head Partial Attention技术,无缝整合头像数据,增强面部表情,无需额外模块。
- 运动和细节优化:通过Phase-specific Denoising Loss(PhD Loss),在不同阶段优化运动表示、外观细节和低级视觉质量。
EchoMimicV2技术原理
- Audio-Pose Dynamic Harmonization (APDH)策略:
- 包括Pose Sampling(姿势采样)和Audio Diffusion(音频扩散),以减少条件复杂性,调节音频和姿势条件。
- 从完整的姿势驱动阶段开始,逐步减少对姿势条件的依赖,同时增强音频条件的控制范围。
- Pose Sampling:
- 通过迭代和空间层面的姿势条件采样,逐步减少对嘴唇、头部和身体部位的关键点控制,为音频驱动过程创造空间。
- Audio Diffusion:
- 在不同阶段逐步整合音频条件,从嘴唇同步开始,逐步扩散到头部和全身,实现音频与手势的相关性。
- Head Partial Attention (HPA):
- 通过在训练中引入头像数据,增强半身数据的面部表情,无需额外的插件或模块。
- Phase-specific Denoising Loss (PhD Loss):
- 将去噪过程分为三个阶段:姿势主导阶段、细节主导阶段和质量主导阶段,并为每个阶段设计特定的损失函数。
- 通过在不同阶段应用不同的损失函数,优化模型的性能,实现更高效和稳定的训练过程。
- Latent Diffusion Model (LDM):
- 使用变分自编码器(VAE)将图像映射到潜在空间,并在训练过程中逐步添加高斯噪声,以估计每个时间步引入的噪声。
- ReferenceNet-based Backbone:
- 利用ReferenceNet从参考图像中提取特征,并将其注入到去噪U-Net中,以保持生成图像与参考图像之间的外观一致性。
- Temporal Modules Optimization:
- 集成时间交叉注意力模块到去噪U-Net中,优化时间模块,以捕捉帧间运动依赖性,实现动画的平滑运动。
EchoMimicV2应用场景
- 虚拟主播:EchoMimicV2可以用于生成虚拟新闻主播或直播主播,他们能够根据实时音频内容同步进行自然的面部和身体动作。
- 电影和游戏制作:在电影或视频游戏的制作中,该技术可以用来创建或增强角色的动画,减少传统动作捕捉的需求。
- 在线教育和培训:EchoMimicV2可以生成模拟教师或培训师的动画,提供更加生动的远程学习体验。
- 客户服务虚拟助手:在客户服务领域,该技术可以用于创建虚拟客服代表,提供更加人性化的交互体验。
- 社交媒体内容创作:用户可以利用EchoMimicV2生成个性化的动画内容,用于社交媒体平台,增加内容的吸引力和互动性。
- 广告和营销:EchoMimicV2可以用于制作动态广告,根据音频广告内容生成吸引人的动画形象,提高广告的吸引力和记忆度。
EchoMimicV2项目入口
- 项目主页:https://antgroup.github.io/ai/echomimic_v2
- GitHub代码库:https://github.com/antgroup/echomimic_v2
- HuggingFace模型:https://huggingface.co/BadToBest/EchoMimicV2
- arXiv技术论文:https://arxiv.org/pdf/2411.10061
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号