LEOPARD简介
LEOPARD是由腾讯AI西雅图实验室推出的一款多模态大型语言模型(MLLM),专门针对包含丰富文本的多图像任务而设计。该模型通过创建一个包含约一百万高质量指令调整数据的LEOPARD-INSTRUCT数据集,以及一个自适应高分辨率多图像编码模块,有效解决了现有模型在处理此类任务时面临的数据稀缺和分辨率与序列长度平衡的挑战。LEOPARD在多个基准测试中展现了卓越的性能,特别是在理解和推理多图像文本内容方面,相较于其他开源模型具有明显优势。
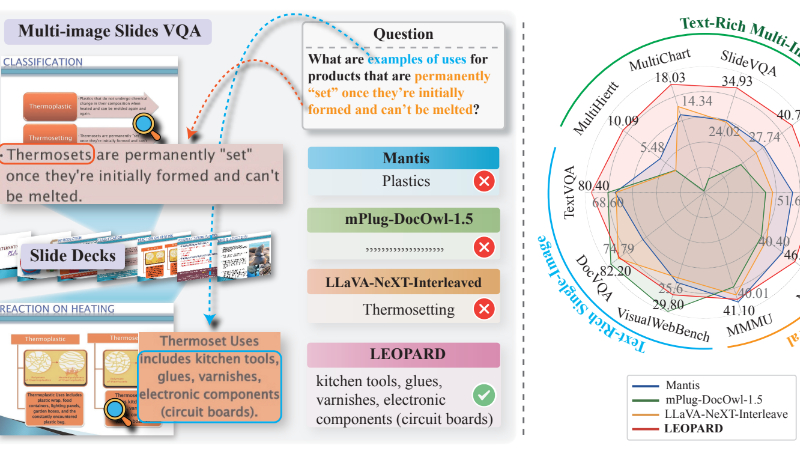
LEOPARD主要功能
- 多图像理解与推理: LEOPARD能够处理和理解包含多个图像的任务,特别是那些图像中文本作为核心视觉元素的场景,如演示文稿、扫描文档和网页截图。
- 跨图像信息整合: 模型能够整合多个页面或图像中的信息,捕捉整个文档或演示的逻辑流程。
- 高分辨率图像处理: 针对文本丰富的图像,LEOPARD能够处理高分辨率图像,以确保文本内容的清晰可读。
- 自适应图像编码: 模型可以动态优化视觉序列长度的分配,适应不同分辨率和纵横比的输入图像。
- 多模态数据集构建: LEOPARD开发了专门的多模态指令调整数据集,用于模型训练和优化。
- 高性能基准测试: 在多个视觉语言任务基准测试中,LEOPARD展现出在文本丰富的多图像任务中的优越性能。
LEOPARD技术原理
- 视觉编码器: 使用视觉编码器从图像中提取高级视觉特征,捕捉关键的语义信息。
- 视觉-语言连接器: 将视觉特征映射到语言表示空间,使视觉和文本信息能够在模型中联合处理。
- 语言模型(LM): 处理交织的文本-视觉令牌序列,利用上下文依赖性生成与两种模态对齐的连贯输出。
- 像素重排(Pixel Shuffling): 通过沿特征维度连接相邻的视觉特征,减少序列长度,以适应更多的图像。
- 自适应高分辨率多图像编码模块: 根据输入图像的原始纵横比和分辨率动态优化视觉序列长度的分配。
- 数据集构建与指令调整: 通过收集和构建专门的多模态数据集,LEOPARD能够针对复杂的多图像场景进行优化。
- 模型架构设计: LEOPARD采用了仅解码器的视觉语言模型架构,包括视觉编码器、视觉-语言连接器和大型语言模型。
LEOPARD应用场景
- 演示文稿理解:LEOPARD能够理解多页演示文稿中的内容,帮助用户把握整个演讲的脉络和关键信息。
- 文档分析:在处理多页文档时,模型能够整合不同页面的信息,以捕捉文档的整体逻辑和细节。
- 学术文章解析:对于包含图表和数据的学术论文,LEOPARD可以提供跨图表和文本的信息整合,辅助研究者快速获取核心观点。
- 网页内容提取:在网页快照分析中,LEOPARD能够识别和理解网页元素及其交互流程,用于自动化网页内容提取和理解。
- 财报分析:对于财务报告等包含大量表格和数字的文档,LEOPARD可以进行数据解析和跨表格计算,辅助财务分析。
- 教育材料开发:在教育领域,LEOPARD可以用于理解和组织教育幻灯片和教材,帮助教师和学生更好地理解和传达知识点。
LEOPARD项目入口
- GitHub代码库:https://github.com/tencent-ailab/Leopard
- HuggingFace模型:https://huggingface.co/datasets/wyu1/Leopard-Instruct
- arXiv技术论文:https://arxiv.org/pdf/2410.01744
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号