SongCreator:由清华大学推出的基于歌词的全能歌曲生成模型
SongCreator简介
SongCreator是由清华大学深圳国际研究生院的一个团队开发的一款先进的歌曲生成模型,它能够根据歌词创作出包含声乐和伴奏的完整歌曲。该系统采用了创新的双序列语言模型(DSLM)和一系列注意力掩码策略,使其在多种歌曲相关生成任务中表现出色,包括从歌词到歌曲、从声乐到歌曲以及歌曲编辑等。SongCreator不仅能够独立控制生成歌曲中声乐和伴奏的声学条件,还展现出在音乐生成领域的广泛应用潜力。
SongCreator主要功能
- 歌词到歌曲生成:根据提供的歌词生成包含声乐和伴奏的完整歌曲。
- 声乐和伴奏协调:生成的声乐和伴奏能够协调一致,形成和谐的音乐作品。
- 音频提示控制:通过不同的音频提示独立控制生成歌曲中声乐和伴奏的声学条件。
- 多任务应用:支持歌词到声乐、伴奏到歌曲、歌曲编辑等多种歌曲生成任务。
- 音频编辑能力:在保持原伴奏不变的情况下编辑歌曲中的声乐部分,或在保持原声乐不变的情况下编辑伴奏部分。
SongCreator技术原理
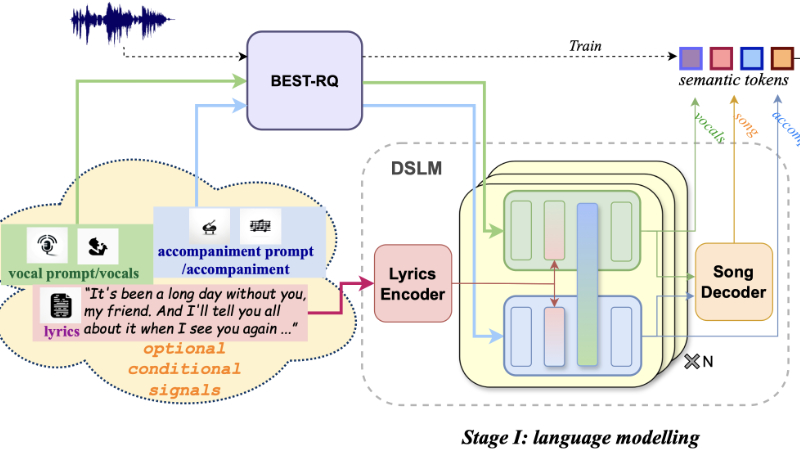
- 双序列语言模型(DSLM):使用两个解码器分别建模声乐和伴奏信息,并通过动态双向交叉注意力模块捕捉两者之间的影响。
- 注意力掩码策略:为DSLM设计了一系列注意力掩码策略,使其能够以统一的方式完成多种形式的歌曲生成任务。
- 潜在扩散模型(LDM):结合了变分自编码器(VAE)和扩散模型,将语义token序列解码成高质量的歌曲音频。
- BEST-RQ与向量量化:使用BEST-RQ模型提取音频数据的语义token,并通过向量量化技术将连续的潜在表示量化为离散的token序列。
- 多任务训练:通过在多个任务上训练模型,增强其在作曲、编曲以及理解声乐和伴奏之间关系的能力。
- 自回归和非自回归预测:在声乐和伴奏的解码器中使用自回归预测来生成token序列,同时在歌曲解码器中使用非自回归方法来整合声乐和伴奏信息。
SongCreator应用场景
- 音乐制作:音乐制作人可以使用SongCreator快速生成歌曲的小样,节省作曲和编曲的时间。
- 音乐教育:在音乐教学中,SongCreator能够帮助学生理解歌曲结构,通过实践学习音乐创作。
- 娱乐互动:在卡拉OK或音乐游戏等娱乐场景中,SongCreator能够根据用户输入的歌词实时生成伴奏。
- 内容创作:视频博主和播客可以利用SongCreator为他们的多媒体内容定制原创背景音乐。
- 广告和影视配乐:广告和电影制作人可以借助SongCreator创作符合场景情感和氛围的配乐。
- 虚拟歌手和乐队:在虚拟偶像或数字乐队的表演中,SongCreator能够提供实时的歌曲生成和伴奏,增强表演的互动性和趣味性。
SongCreator项目入口
- 项目主页:https://songcreator.github.io/
- arXiv技术论文:https://arxiv.org/pdf/2409.06029
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号