Freestyler:能够直接从歌词和伴奏输入生成说唱声乐
Freestyler简介
Freestyler是由中国西北工业大学音频、语音与语言处理小组(ASLP@NPU)与微软中国合作开发的一款创新系统,它能够直接从歌词和伴奏输入生成说唱声乐。这一技术突破使得用户无需具备音乐知识即可创作出与伴奏风格和节奏高度一致的高质量说唱音乐,展现了人工智能在音乐创作领域的新进展。
Freestyler主要功能
- 说唱声乐生成:Freestyler能够直接从歌词和伴奏输入生成说唱声乐。
- 零样本音色控制:通过3秒的参考音频,Freestyler能够适应任何说话者的音色,实现零样本控制。
- 风格和节奏对齐:生成的说唱声音与伴奏的风格和节奏高度一致。
- 数据集创建:解决了公开可用说唱数据集稀缺的问题,创建了RapBank数据集。
Freestyler技术原理
- 三阶段框架:
- 歌词到语义(Lyrics-to-Semantic):使用语言模型基于歌词和伴奏特征生成离散的语义标记。
- 语义到频谱图(Semantic-to-Spectrogram):应用条件流匹配技术将语义标记转换成连续的mel-spectrogram。
- 频谱图到音频(Spectrogram-to-Audio):使用神经声码器从频谱图中恢复音频。
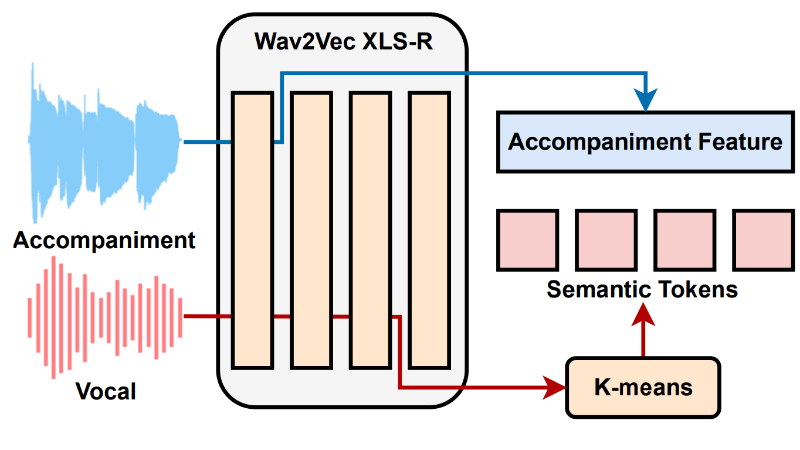
- 语义标记生成:利用自监督学习(SSL)表示的K-means聚类作为代理特征,以减少对标注数据的依赖。
- 条件流匹配(Conditional Flow Matching, CFM):用于将离散的语义标记映射到连续的mel-spectrogram。
- 神经声码器(Neural Vocoder):用于从mel-spectrogram重建音频,Freestyler使用的是BigVGAN-V2。
- 伴奏特征和语义标记的对齐:通过将伴奏特征向左移动K帧来提供额外的节奏上下文,以改善生成的说唱声乐与伴奏的匹配度。
- 随机掩码(Random Masking):为了解决训练和推理时声音-伴奏对长度不匹配的问题,引入随机掩码以减少两者之间的强时间相关性。
- 参考音频条件:在歌词到语义和语义到频谱图阶段引入参考音频条件,以补充语义标记中缺失的音色信息。
- 数据收集和处理:开发了自动化流程来收集和标记RapBank数据集,包括从YouTube爬取数据、源分离、分割、歌词识别和质量过滤。
Freestyler应用场景
- 音乐制作:音乐制作人和艺术家可以使用Freestyler快速生成说唱部分,加速音乐创作流程。
- 虚拟歌手:在虚拟偶像或虚拟乐队中,Freestyler可以为虚拟角色生成自然的说唱表演。
- 教育和学习:在音乐教育中,Freestyler可以作为教学工具,帮助学生理解说唱的节奏和风格。
- 娱乐互动:在卡拉OK或游戏应用中,Freestyler可以让用户即兴创作说唱,增加娱乐性。
- 广告和营销:企业可以利用Freestyler生成定制的说唱广告曲,以吸引年轻受众。
- 语言技术研究:研究人员可以使用Freestyler来探索语音合成、音乐信息检索和自然语言处理的新技术
Freestyler项目入口
- GitHub仓库:https://github.com/NZqian/RapBank
- arXiv技术论文:https://arxiv.org/pdf/2408.15474
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号