EDTalk简介
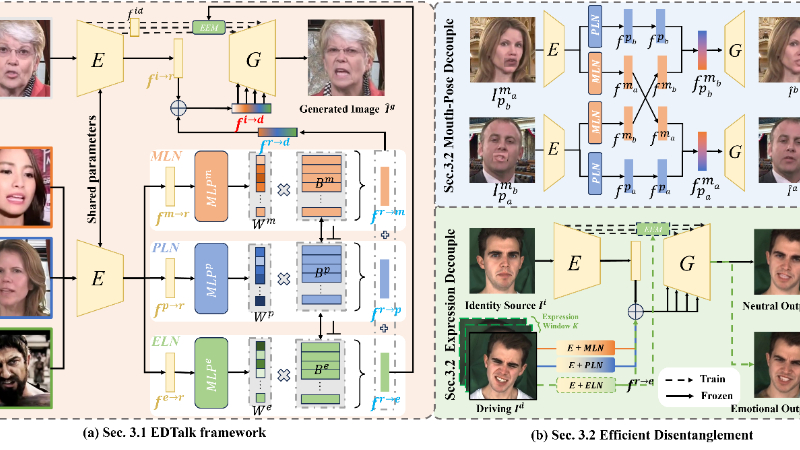
EDTalk是由上海交通大学与网易伏羲人工智能实验室联合开发的高效解耦框架,旨在提升情感头像合成的应用性和娱乐性。该框架能够独立控制嘴型、头部姿态和情感表达,支持视频和音频输入,通过三个轻量级模块将面部动态分解为代表嘴部、姿态和表情的独立潜在空间,实现精细操控。EDTalk采用正交基和高效训练策略,无需外部知识即可完成训练,显著提升了训练效率,并在多模态应用中展现出卓越的性能。
主要功能
- 独立操控面部动作:EDTalk能够独立控制嘴型、头部姿态和情感表达,提供精细的面部动作调节。
- 多模态输入支持:框架支持视频和音频输入,可以根据不同输入模式生成相应的头像动画。
- 情感头像合成:能够根据音频或视频中的情感内容生成匹配的面部表情,增强头像的真实感和表现力。
- 音频驱动的头像生成:通过Audio-to-Motion模块,EDTalk可以直接从音频输入生成具有同步唇动和情感表达的头像视频。
- 高效训练策略:采用渐进式训练策略,减少了训练时间和计算资源的需求。
技术原理
- 潜在空间解耦:将面部动态分解为三个独立的潜在空间,分别对应嘴部、姿态和表情,实现面部动作的独立控制。
- 正交基约束:在每个潜在空间内,通过正交基约束确保不同空间之间的独立性,避免相互干扰。
- 渐进式训练策略:
- 口型-姿态解耦:通过交叉重建技术分离嘴型和头部姿态。
- 表情解耦:利用自重建互补学习进一步分离表情信息。
- Audio-to-Motion模块:
- 音频驱动的唇动生成:使用音频编码器和MLP预测嘴部基的权重,实现唇动与音频的同步。
- 基于流的头姿态生成:利用正规化流模型预测头部姿态的权重,生成多样化的头部动作。
- 语义感知的表情生成:结合音频和文本输入,预测表情权重,生成与情感内容匹配的表情。
- 存储和共享视觉先验:学习到的基被存储在相应的基库中,为音频驱动的头像生成提供共享的视觉先验。
- 端到端重建:通过编码器和生成器的端到端框架,直接从输入重建头像视频,简化了处理流程并提高了效率。
应用场景
- 虚拟主播:在新闻播报或直播中,使用EDTalk生成的虚拟主播可以模仿真人主播的面部动作和表情,提供更加自然和吸引人的观看体验。
- 电影制作:在电影后期制作中,EDTalk可以用来创建或修改角色的面部表情和动作,以适应特定的情感场景,增强角色的表现力。
- 在线教育:在在线课程中,EDTalk可以生成具有教育性表情和动作的虚拟教师,使学习过程更加互动和有趣。
- 视频会议:在远程工作和视频会议中,EDTalk可以增强参与者的头像,使其表情和唇动与语音同步,提升沟通的自然感。
- 游戏和娱乐:在电子游戏中,EDTalk可以用于生成具有丰富表情和动作的NPC角色,提升游戏的沉浸感和互动性。
- 社交媒体:用户可以利用EDTalk在社交媒体上创建个性化的虚拟形象,这些形象能够根据用户的语音输入实时展现相应的表情和动作。
项目入口
- 项目主页:https://tanshuai0219.github.io/EDTalk
- Github代码库:https://github.com/tanshuai0219/EDTalk
- arXiv技术论文:https://arxiv.org/pdf/2404.01647
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号