ILLUME简介
ILLUME是由华为诺亚方舟实验室开发的一款创新的统一多模态大型语言模型(MLLM),它通过集成多模态理解和生成能力,能够在单一的大型语言模型框架内实现图像和文本的无缝对接。该模型通过设计具有语义信息的视觉分词器和采用渐进式多阶段训练方法,显著提高了数据效率,并在减少预训练数据需求的同时,达到了与现有先进模型相竞争甚至更优的性能。此外,ILLUME还引入了自增强多模态对齐方案,进一步提升了模型在多模态任务中的准确性和可靠性。
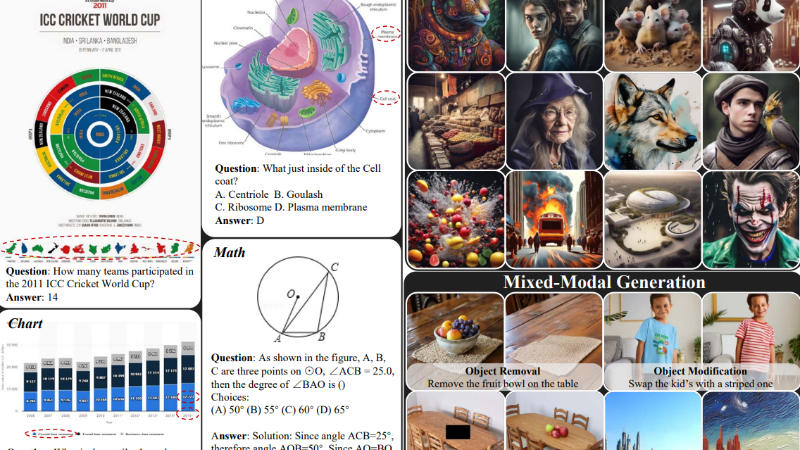
ILLUME主要功能
- 多模态理解与生成能力:ILLUME能够理解和生成图像与文本,实现多模态数据处理的无缝整合。
- 视觉分词器设计:通过视觉分词器将图像转换为模型可以理解的离散令牌,提高了数据效率。
- 渐进式多阶段训练:采用分阶段训练方法,先初始化视觉嵌入,再进行图像-文本对齐,最后进行监督微调,以提高模型性能。
- 自增强多模态对齐:通过自我评估文本描述与自生成图像之间的一致性,提升模型的准确性和可靠性。
- 广泛的任务适应性:能够处理各种多模态任务,包括图像理解、文本到图像的生成以及混合模态生成任务(如对象修改和风格转换)。
ILLUME技术原理
- 统一下一个词预测公式:ILLUME使用统一的下一个词预测公式来整合多模态理解和生成能力,使得模型能够预测文本或视觉令牌序列中的下一个元素。
- 语义信息融合:通过设计视觉分词器,将图像量化为包含语义信息的离散令牌,加速了图像-文本对齐过程。
- 特征重建损失:在视觉分词器中,使用特征重建损失(包括余弦损失和平滑L1损失)来监督量化过程,确保图像特征的准确恢复。
- 条件扩散模型:使用条件扩散模型(如Stable Diffusion)从离散令牌中重建高分辨率图像,补偿量化过程中丢失的细节。
- 自增强学习机制:通过自我评估生成的图像与文本描述之间的一致性,模型能够识别自身在图像生成中的不足,并据此进行自我改进。
- 多阶段训练策略:包括视觉嵌入初始化、统一图像-文本对齐和监督微调三个阶段,逐步提升模型对多模态数据的理解和生成能力。
- 交互式数据增强:通过自我生成的图像和对应的文本描述之间的对比,生成用于训练的数据,进一步提升模型性能。
ILLUME应用场景
- 图像识别与描述:ILLUME可以识别图像内容并生成相应的文本描述,适用于图像标注和自动化内容生成。
- 文本到图像的生成:根据给定的文本提示生成相应的图像,用于创意设计、广告制作和游戏开发等领域。
- 图像编辑与增强:对现有图像进行编辑,如风格转换、对象移除或颜色修改,应用于照片编辑和视觉艺术创作。
- 文档图像处理:在文档扫描和数字化过程中,ILLUME可以识别和编辑图像中的文字和图表,提高文档处理的自动化水平。
- 交互式问答系统:在问答系统中,ILLUME能够理解用户上传的图像内容并提供相关信息,增强用户体验。
- 辅助设计和创作:艺术家和设计师可以利用ILLUME生成创意草图或设计元素,加速创作过程并探索新的视觉表现手法。
ILLUME项目入口
- arXiv技术论文:https://arxiv.org/pdf/2412.06673
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号