VITRON:Skywork AI联合新加坡国立大学等推出的视觉大型语言模型
VITRON简介
VITRON是由Skywork AI、新加坡国立大学和南洋理工大学联合推出的像素级视觉大型语言模型(LLM),它能够全面理解、生成、分割和编辑静态图像及动态视频。该模型通过结合最新的视觉专家系统和大型语言模型,支持从低级到高级的广泛视觉任务,实现了图像和视频的统一处理。VITRON采用混合方法传递信息,同时利用离散文本指令和连续信号嵌入,确保精确的功能调用和执行。此外,它还通过跨任务协同模块,优化了不同视觉任务间细粒度视觉特征的共享,展现了在多模态视觉语言任务中的卓越性能。
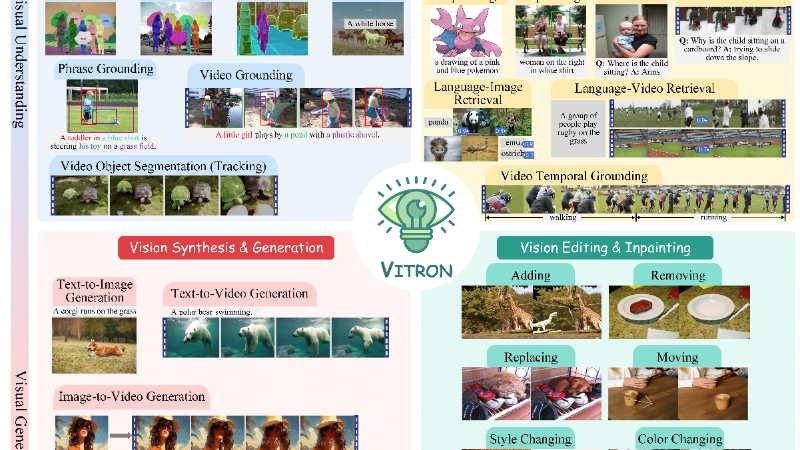
VITRON主要功能
- 视觉理解(Visual Understanding):VITRON能够理解图像和视频内容,包括低级视觉语义和高级视觉语义。
- 视觉生成(Visual Generation):模型支持从文本到图像和从文本到视频的生成,以及图像和视频的风格变换。
- 视觉分割与定位(Vision Segmentation & Grounding):VITRON能够进行像素级的图像和视频分割,以及对特定区域的语义定位。
- 视觉编辑(Vision Editing):模型具备对图像和视频进行添加、替换、移除和颜色改变等编辑操作的能力。
- 多轮上下文交互(Multi-turns Context & Conversation):支持与用户的多轮交互,以实现更精细的视觉任务操作。
- 图像-视频互转换(Image-Video Interconversion):能够在图像和视频之间进行转换,以支持不同的视觉内容创作需求。
VITRON技术原理
- 编码器集成(Encoder Integration):VITRON整合了图像、视频和像素级区域视觉编码器,以处理和理解视觉信号。
- 大型语言模型(Large Language Model):使用Vicuna(7B, 版本1.5)作为中心代理,处理多模态输入并执行语义理解和决策。
- 混合方法指令传递(Hybrid Method for Instruction Passing):结合离散文本指令和连续信号特征嵌入,以精确地向下游模块传递LLM的决策。
- 像素级时空对齐学习(Pixel-level Spatiotemporal Vision-language Alignment Learning):通过训练LLM在像素级别上对图像和视频进行空间和时间的对齐,以增强模型的细粒度视觉感知能力。
- 跨任务协同模块(Cross-task Synergy Module):通过共享任务不变细粒度视觉特征,实现不同视觉任务间的协同效应,提升模型性能。
- 对抗训练(Adversarial Training):使用对抗训练来分离任务特定特征和任务不变细粒度特征,以优化特征表示并增强任务间的协同作用。
VITRON应用场景
- 图像和视频编辑:用户可以通过文本指令对图像或视频进行精确编辑,如移除背景中的物体或更改对象颜色。
- 内容创作:从文本描述生成图像和视频,为数字艺术和媒体制作提供新的内容创作工具。
- 视觉问答(Visual QA):对图像或视频内容进行问答,适用于教育平台和智能助手,提供基于视觉内容的互动体验。
- 视频内容分析:分析视频内容,识别和跟踪对象,适用于安全监控和行为分析领域。
- 图像检索:基于文本描述检索图像或视频,提高搜索引擎的准确性和效率。
- 自动化设计:根据文本描述自动生成设计草图,辅助设计师快速实现创意构思。
VITRON项目入口
- 项目主页:https://vitron-llm.github.io/
- GitHub代码库:https://github.com/SkyworkAI/Vitron
- arXiv技术论文:https://arxiv.org/pdf/2412.19806
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号