REEF:帮助保护大型语言模型的知识产权
REEF简介
REEF(REpresentation Encoding Fingerprints)是由上海人工智能实验室开发的一种新型工具,旨在保护大型语言模型(LLMs)的知识产权。通过比较疑似模型和受害模型在相同样本上的表示之间的中心核对齐(CKA)相似度,REEF能够在无需重新训练的情况下,有效识别模型间的关联。这种方法对微调、剪枝、模型合并和置换等操作表现出鲁棒性,为模型所有者和第三方提供了一种简单而有效的知识产权保护手段。
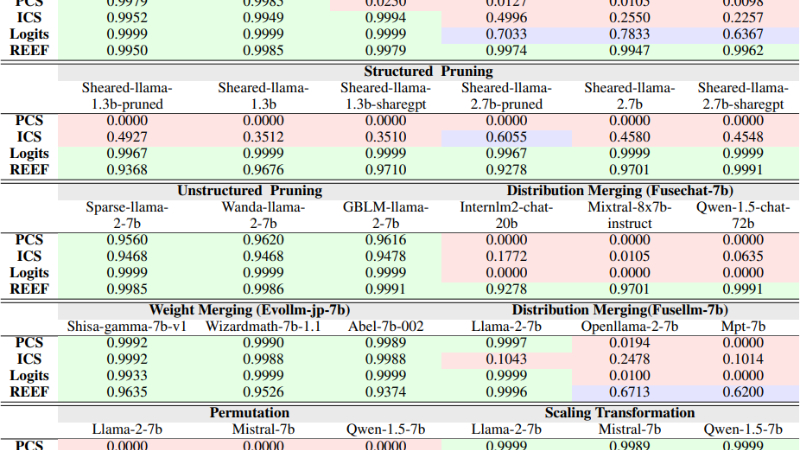
REEF主要功能
- 模型关系识别:REEF能够识别疑似模型是否是基于某个特定的受害模型(victim model)开发的后续版本。
- 知识产权保护:通过识别模型间的相似性,REEF帮助保护大型语言模型的知识产权,防止未经授权的使用或复制。
- 无需训练的模型分析:REEF不需要对模型进行额外的训练,即可进行分析,减少了资源消耗。
- 鲁棒性:REEF对于模型的各种后续处理,如微调、剪枝、模型合并和参数置换等,都能保持较高的识别准确率。
REEF技术原理
- 表示对齐:REEF基于大型语言模型(LLMs)的特征表示,通过比较疑似模型和受害模型在相同输入样本上的表示来分析它们之间的关系。
- 中心核对齐(CKA):REEF使用中心核对齐(Centered Kernel Alignment)方法来计算两个模型表示之间的相似度。CKA是一种基于Hilbert-Schmidt Independence Criterion(HSIC)的相似度度量方法。
- 核函数选择:REEF支持线性核和径向基函数(RBF)核,用于计算表示之间的相似性。线性核通过计算Gram矩阵(即表示矩阵的内积)来实现,而RBF核则基于样本对之间的欧氏距离。
- 理论证明:REEF提供了理论证明,表明CKA相似度对于列置换和列缩放变换是不变的,这意味着即使在模型表示的维度发生变化或被恶意操纵的情况下,REEF仍然有效。
- 实验验证:REEF通过一系列实验验证了其有效性,包括在不同数据集和模型变体上测试CKA相似度,以及评估对模型剪枝、合并和置换等操作的鲁棒性。
REEF应用场景
- 开源模型验证:确保开源的大型语言模型(LLMs)在发布时保持其原创性,防止基于他人模型的未经授权修改和发布。
- 版权保护:帮助模型开发者和所有者识别和证明他们的模型是否被非法复制或未经授权的使用,从而保护知识产权。
- 合规性检查:使监管机构能够验证模型是否符合特定的许可要求,例如Apache 2.0或LLaMA 2社区许可证。
- 模型开发追溯:在模型开发过程中,通过REEF追踪模型的变化,确保模型的迭代开发是基于合法和合规的框架。
- 学术研究:在学术领域,REEF可以用来比较不同研究团队发布的模型,以识别原创性和避免学术不端行为。
- 企业合作:在企业间合作开发语言模型时,REEF可以作为工具来确认各方贡献的模型是否被正确使用和归属。
REEF项目入口
- arXiv技术论文:https://arxiv.org/pdf/2410.14273
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号