Video-RAG:助力视频语言模型更好地理解和处理长视频内容
Video-RAG简介
Video-RAG是一种创新的无需训练且成本效益高的视频理解流程,旨在解决大型视频-语言模型(LVLMs)在理解长视频时因上下文有限而遇到的挑战。该方法通过视觉对齐的辅助文本帮助跨模态对齐,并提供超出视觉内容的额外信息。具体而言,Video-RAG利用开源外部工具从纯视频数据中提取音频、光学字符和目标检测等视觉对齐信息,并将这些信息作为辅助文本与视频帧和查询一起输入到现有的LVLM中。通过这种插件式集成,Video-RAG显著提升了长视频理解的性能,尤其在Video-MME、MLVU和LongVideoBench等基准测试中表现出色,甚至在与72B模型结合使用时,性能超过了专有模型如Gemini1.5-Pro和GPT-4o。此外,Video-RAG具有轻量级、易于实现和兼容性强等优点,为长视频理解提供了一种资源高效且灵活的解决方案.
Video-RAG主要功能
- 长视频理解:能够有效理解长视频内容,解决传统LVLMs因上下文限制导致的理解困难问题.
- 跨模态对齐:通过视觉对齐的辅助文本,促进视频内容与文本查询之间的跨模态对齐,提高理解准确性.
- 性能提升:在多个长视频理解基准测试中,如Video-MME、MLVU和LongVideoBench等,显著提升LVLMs的性能.
- 开源兼容:完全基于开源工具和模型实现,无需依赖专有模型或商业API,易于集成和扩展.
- 资源高效:采用单次检索的方式,具有较低的计算开销和资源消耗,相较于传统方法更加高效.
Video-RAG技术原理
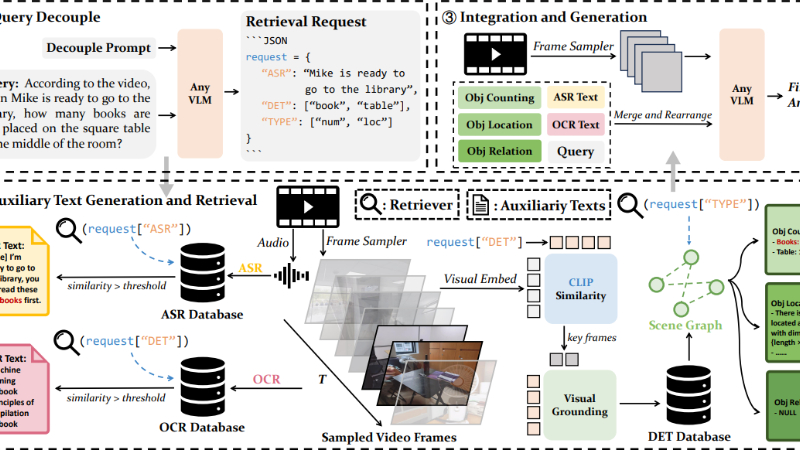
- 查询解耦:
- 接收用户关于视频的查询后,LVLM首先解耦查询并生成检索请求,用于从目标视频中提取辅助文本.
- 通过解耦提示(prompt),LVLM生成包含自动语音识别(ASR)、目标检测(DET)和类型(TYPE)等信息的JSON格式检索请求.
- 辅助文本生成与检索:
- 从查询视频中并行生成多种辅助文本,包括光学字符识别(OCR)、自动语音识别(ASR)和目标检测(DET)文本.
- 构建OCR、ASR和DET数据库,利用Contriever模型将文本编码成文本嵌入,并存储在FAISS索引库中以支持高效的相似性搜索.
- 根据检索请求,从数据库中检索与用户查询相关的辅助文本,确保其在文本嵌入空间中的相关性.
- 集成与生成:
- 将检索到的辅助文本与用户的查询结合,形成统一的辅助输入.
- 将辅助输入与视频帧一起输入到LVLM中,生成最终的响应结果,辅助文本帮助LVLM更好地理解和生成与查询相关的信息.
Video-RAG应用场景
- 视频内容审核:在长视频平台或社交媒体中,利用Video-RAG自动理解视频内容,高效识别违规、不当或敏感信息,辅助人工审核提高审核效率和准确性.
- 教育视频分析:应用于在线教育领域,对教学视频进行深入理解,提取关键知识点、教学环节等信息,帮助学生快速定位学习重点,辅助教师优化教学内容.
- 影视制作辅助:在影视后期制作过程中,通过Video-RAG分析视频素材,自动整理和分类镜头,提取人物对白、场景描述等信息,为剪辑、特效制作等环节提供参考和便利.
- 视频推荐系统:结合用户的兴趣和行为数据,利用Video-RAG深入理解视频内容,精准推荐相关性强、用户感兴趣的长视频,提升用户体验和平台的用户粘性.
- 视频问答系统:构建基于Video-RAG的视频问答系统,用户可以针对长视频内容提出具体问题,系统通过理解视频和问题,给出准确的答案,满足用户对视频信息的查询需求.
- 视频内容创作:辅助视频创作者在创作过程中,通过Video-RAG分析已有视频素材,提取创意点、素材标签等信息,为创作新视频提供灵感和素材推荐,提高创作效率和质量.
Video-RAG项目入口
- 项目主页:https://video-rag.github.io/
- Github代码库:https://github.com/Leon1207/Video-RAG-master
- arXiv技术论文:https://arxiv.org/pdf/2411.13093
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号