Mobile-Agent:能够准确定位移动设备屏幕上的视觉和文本元素
Mobile-Agent简介
Mobile-Agent是一种自主多模态移动设备代理,基于多模态大型语言模型(MLLM)开发,具备强大的视觉感知能力。它通过视觉感知模块,仅使用移动设备的屏幕截图,就能准确定位操作位置,无需依赖系统代码或底层文件,实现了完全基于视觉的解决方案。Mobile-Agent能够根据屏幕截图、用户指令和操作历史,自主规划和分解复杂任务,逐步导航移动应用完成操作。此外,它还具备自我反思功能,能够识别错误操作和不完整指令,并在指令完成后停止操作。在Mobile-Eval基准测试中,Mobile-Agent展示了出色的完成率和操作准确性,即使面对多应用操作等复杂指令也能成功完成任务,证明了其在不同移动操作系统环境中强大的适应性和作为通用移动设备代理的潜力.
Mobile-Agent主要功能
- 视觉感知定位:能够准确定位移动设备屏幕上的视觉和文本元素,包括文本和图标的位置,为后续操作提供精确的目标位置.
- 自主任务规划:基于用户指令、屏幕截图和操作历史,自主规划和分解复杂任务,逐步导航移动应用完成操作,无需人工干预.
- 自我反思与纠错:在操作过程中,能够识别错误操作和不完整指令,及时进行自我反思和纠错,确保任务顺利完成.
- 跨应用操作:支持同时使用多个应用,能够在不同应用之间传递信息,完成跨应用的任务,如从一个应用获取信息并在另一个应用中使用.
- 多语言支持:具备一定的多语言处理能力,能够理解和执行简单的中文指令,尽管在处理复杂中文场景时可能存在一些限制.
Mobile-Agent技术原理
- 视觉感知模块:
- 检测模型:用于识别屏幕上的图标位置,结合CLIP模型计算图标与描述的相似度,选择最匹配的图标区域进行点击操作.
- OCR模型:用于检测屏幕上的文本位置,根据OCR检测结果的不同情况(如未检测到指定文本、检测到一个实例或多实例),采取相应的操作策略,如重新选择文本或在多个实例中选择一个进行点击.
- 自我规划机制:
- 基于GPT-4V的强大上下文理解和推理能力,结合系统提示、操作历史和当前屏幕截图,生成下一步操作指令,实现迭代的自我规划过程.
- 通过定义八种基本操作(如打开应用、点击文本、点击图标、输入文本等),将代理输出的动作转换为具体的屏幕操作.
- 自我反思方法:
- 当检测到操作后屏幕未发生变化或出现错误页面时,提示代理尝试替代操作或修改当前操作参数,以纠正错误操作.
- 在完成所有操作后,指导代理分析操作、历史、当前截图和用户指令,判断指令是否已完成,若未完成则继续生成操作.
- 提示格式设计:
- 参考ReAct的提示格式,要求代理输出三个组件:观察(Observation)、思考(Thought)和行动(Action),分别描述当前截图和操作历史、基于观察和指令考虑的下一步操作以及选择的具体操作和参数,以更好地实现功能.
Mobile-Agent应用场景
- 在线购物:用户可以指示Mobile-Agent在电商平台(如Alibaba.com)上搜索特定商品(如帽子),并自动完成添加到购物车等操作.
- 音乐播放:在音乐应用(如Amazon Music)中,根据用户喜好搜索特定歌手(如周杰伦)的音乐或与“代理”相关的歌曲,并播放.
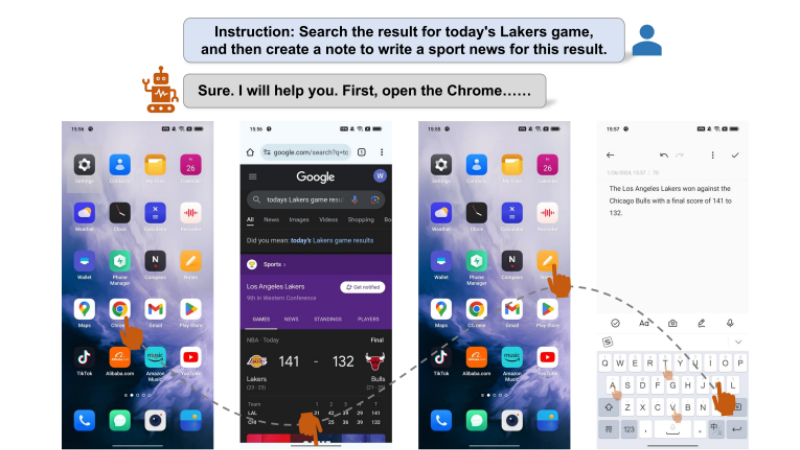
- 信息查询:利用浏览器(如Chrome)搜索当天湖人队的比赛结果或泰勒·斯威夫特的相关信息,为用户提供最新资讯.
- 邮件发送:在邮件应用(如Gmail)中,根据用户提供的地址,发送空邮件或包含特定内容(如告知新工作)的邮件.
- 导航定位:通过地图应用(如Google Maps)导航到目的地(如杭州西湖)或附近的加油站,为用户出行提供便利.
- 应用下载:在应用商店(如Google Play)中,根据用户需求下载特定应用(如WhatsApp或Instagram),简化用户操作流程.
Mobile-Agent项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号