MultiBooth:能够根据包含多个概念的文本提示生成相应的图像
MultiBooth简介
MultiBooth是由清华大学深圳国际研究生院、Meta Platforms Inc.、香港科技大学和杜克大学联合开发的一项创新技术,旨在解决多概念文本到图像生成中的概念保真度低和推理成本高的问题。该方法采用两阶段策略:单概念学习阶段和多概念整合阶段。在单概念学习阶段,通过多模态图像编码器和高效的概念编码技术,为每个概念学习一个简洁且具有区分性的表示,并利用自适应概念归一化(ACN)解决嵌入空间的域差异问题。在多概念整合阶段,提出区域定制化模块(RCM),在交叉注意力层中将多个单概念模块有效结合,生成多概念图像。MultiBooth在定性和定量实验中均展现出优越的性能,能够以高保真度和低推理成本生成符合文本提示的多概念图像,为文本到图像生成领域提供了新的解决方案。
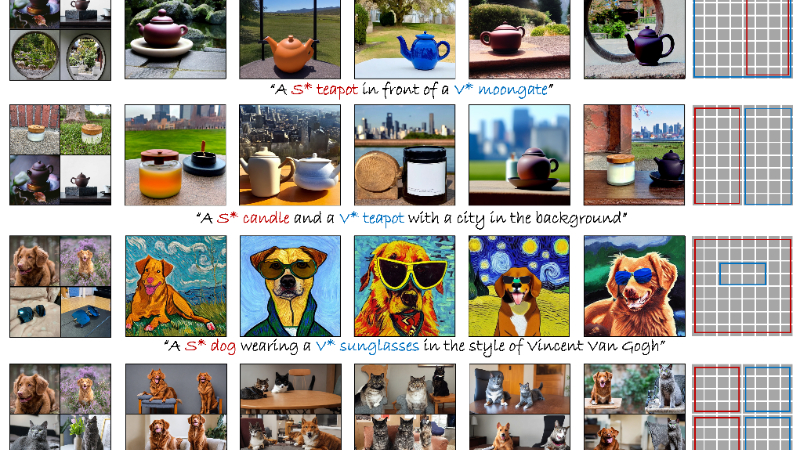
MultiBooth主要功能
-
多概念文本到图像生成:能够根据包含多个概念的文本提示生成相应的图像,满足用户在不同场景下对多个特定概念的定制化需求.
-
高保真度图像生成:生成的图像具有较高的保真度,能够准确地反映文本提示中的各个概念及其细节特征.
-
灵活的多概念组合:支持任意组合多个单概念模块,实现多样化的多概念图像生成,适应不同用户的需求和创意.
-
低推理成本:在多概念生成过程中,推理成本较低,不会因为概念数量的增加而导致显著的性能下降.
MultiBooth技术原理
-
两阶段策略:
-
单概念学习阶段:
-
多模态图像编码器:采用QFormer编码器,输入图像和概念名称,通过自注意力层和交叉注意力层的交互,生成与文本对齐的定制化嵌入,为每个概念学习一个简洁且具有区分性的表示.
-
自适应概念归一化(ACN):调整定制化嵌入的L2范数,使其与提示中的其他词嵌入具有可比性,解决嵌入空间的域差异问题,提高模型的多概念生成能力.
-
高效概念编码:利用LoRA技术对U-Net中的注意力层进行低秩分解,提高概念保真度,避免因微调U-Net导致的语言漂移,同时减少参数数量和计算量.
-
-
多概念整合阶段:
-
区域定制化模块(RCM):在交叉注意力层中,根据基提示和区域提示,将多个单概念模块有效结合,生成多概念图像。RCM通过将注意力图划分为不同区域,并在每个区域内生成对应的概念,允许不同概念在重叠区域准确交互,实现灵活且精确的多概念定制化.
-
注意力机制:在RCM中,利用注意力机制对查询、关键和值向量进行操作,得到包含文本指导和概念信息的图像特征,确保生成的图像与文本提示高度对齐.
-
-
MultiBooth应用场景
-
个性化产品设计:根据用户提供的个性化需求和风格偏好,生成定制化的商品设计图,如个性化T恤、杯子等,帮助设计师快速呈现设计思路.
-
虚拟角色创建:在游戏或虚拟社交平台中,根据用户的描述生成独特的虚拟角色形象,包括角色的外观特征、服饰风格等,提升用户的沉浸感和个性化体验.
-
创意内容制作:为内容创作者提供灵感和素材,根据创意文本生成相关的图像内容,如插画、海报等,辅助创作者丰富作品的视觉表现.
-
教育与学习:在教学过程中,根据教学内容生成相应的图像辅助材料,如历史事件的场景再现、科学概念的可视化等,帮助学生更好地理解和记忆知识.
-
广告与营销:为广告主根据广告文案生成吸引人的广告图像,突出产品特点和卖点,提高广告的吸引力和传播效果.
-
旅游与文化推广:根据旅游景点的介绍或文化故事生成相关的图像,用于旅游宣传册、文化展览等,展示景点特色和文化内涵,吸引游客和观众.
MultiBooth项目入口
- 项目主页:https://multibooth.github.io/
- GitHub代码库:https://github.com/chenyangzhu1/MultiBooth
- arXiv技术论文:https://arxiv.org/pdf/2404.14239
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号