Seer:实现对机器人动作的高效学习和精准预测
Seer简介
Seer是由上海人工智能实验室、北京大学计算机学院、北京大学软件与微电子学院、香港中文大学等机构联合开发的一款先进的机器人操控模型。该模型基于端到端的预测逆动力学模型(PIDM),通过将视觉和动作在训练和推理过程中形成闭环,实现了对机器人动作的高效学习和精准预测。Seer利用Transformer架构处理视觉状态和动作信息,通过预知令牌和动作令牌的协同工作,能够预测未来的视觉状态并据此调整动作策略。在大规模机器人数据集DROID上预训练后,Seer在仿真和真实世界任务中均表现出优异的性能和泛化能力,特别是在复杂场景下的鲁棒性和数据效率方面具有显著优势,为机器人操控领域的发展提供了新的技术路径。
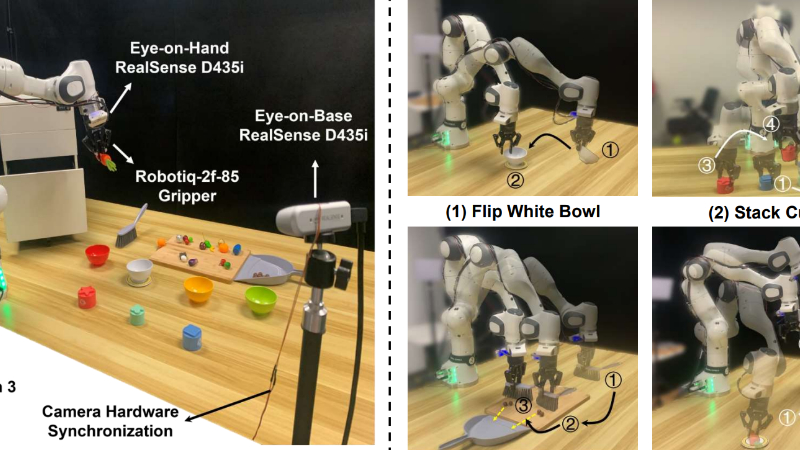
Seer主要功能
- 动作预测:能够根据当前的视觉状态和目标信息,预测出合适的机器人动作,以完成指定的任务.
- 视觉预知:可以预测未来的视觉状态,即在执行动作之前,提前感知到动作可能带来的视觉变化,从而更好地规划动作序列.
- 闭环控制:将视觉和动作紧密结合,在训练和推理过程中形成闭环,使得模型能够根据实时的视觉反馈调整动作策略,提高操控的准确性和稳定性.
- 泛化与适应:在大规模机器人数据集上预训练后,能够适应不同的任务场景和环境变化,即使在数据稀缺的情况下也能表现出较好的泛化能力,快速微调以应对新的挑战.
- 鲁棒性:在面对各种干扰因素,如不同颜色的物体、复杂的背景、光照变化等,仍能保持较好的性能,准确执行任务,显示出较强的鲁棒性.
Seer技术原理
- 端到端学习:采用端到端的学习方式,直接从输入的视觉状态和目标信息到输出的动作,省去了传统方法中繁琐的特征提取和动作规划步骤,使得模型能够更高效地学习从感知到执行的映射关系.
- Transformer架构:利用Transformer架构处理视觉状态和动作信息,借助其强大的序列建模能力和自注意力机制,能够捕捉到视觉和动作之间的复杂依赖关系,同时处理多模态数据,实现对视觉信息和动作序列的深度融合.
- 预知令牌与动作令牌:引入预知令牌(foresight token)和动作令牌(action token),预知令牌用于预测未来的视觉状态,动作令牌用于估计当前和预测未来观测之间的中间动作。这两个令牌与输入的RGB图像、机器人状态和语言令牌通过多模态编码器融合,实现对视觉和动作信息的协同处理.
- 单向注意力掩码:设计了单向注意力掩码,使动作令牌能够深度融合过去和未来的预测信息,这有助于模型在推理过程中更好地利用历史信息和未来预期,从而提高动作预测的准确性和一致性.
- 大规模预训练与微调:在大规模机器人数据集(如DROID)上进行预训练,使模型学习到丰富的视觉和动作先验知识,然后通过少量微调数据适应具体任务,这种预训练加微调的策略能够有效提高模型的泛化能力和数据效率.
Seer应用场景
- 工业自动化装配:在电子元件装配、汽车零部件组装等工业生产线上,Seer可以精准控制机器人手臂,根据视觉识别的元件位置和姿态,自动完成拾取、定位、插入等装配动作,提高生产效率和装配质量.
- 物流分拣与搬运:在物流仓库中,Seer能够识别不同类型的货物,如包裹、箱子等,指导机器人进行快速分拣、搬运和码垛,适应复杂的货物摆放和多变的环境条件,降低人工成本,提升物流效率.
- 服务机器人任务:在餐饮、零售等服务行业,Seer可以驱动服务机器人完成上菜、收银、清洁等任务。例如,在餐厅中,机器人可以根据视觉信息识别菜品位置,准确地将菜品送到顾客桌上,提供便捷的服务.
- 医疗辅助操作:在医疗领域,Seer可以辅助医生进行手术、康复训练等操作。例如,在手术中,机器人可以在医生的指导下,根据视觉信息精准定位手术部位,协助完成缝合、打结等精细动作,提高手术的安全性和成功率.
- 农业采摘与种植:在农业生产中,Seer能够识别成熟的果实、蔬菜等,指导机器人进行采摘、种植等作业。如在果园中,机器人可以根据视觉信息判断果实的成熟度和位置,自动完成采摘动作,提高农业生产的自动化水平.
- 灾难救援与探索:在地震、火灾等灾难现场,Seer可以控制机器人进入危险区域进行救援和探索。机器人能够根据视觉信息识别被困人员、障碍物等,规划救援路径,执行救援任务,如搬运重物、打开通道等,为救援工作提供有力支持.
Seer项目入口
- 项目主页:https://nimolty.github.io/Seer
- GitHub代码库:https://github.com/OpenRobotLab/Seer
- arXiv技术论文:https://arxiv.org/pdf/2412.15109
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号