STAR:将低分辨率的现实世界视频恢复成高分辨率版本
STAR简介
STAR是由南京大学、字节跳动和西南大学联合开发的一种新颖的现实世界视频超分辨率(VSR)框架。该框架通过整合强大的文本到视频(T2V)扩散模型,旨在恢复具有逼真空间细节和稳健时间一致性的高质量视频。STAR引入了局部信息增强模块(LIEM),在全局注意力块前对局部细节进行丰富,有效减轻现实场景中复杂退化带来的伪影问题。此外,它还提出了动态频率(DF)损失,引导模型在不同扩散步骤中关注不同频率成分,从而提高恢复结果的保真度。通过在合成和现实世界数据集上的广泛实验,STAR在多个评估指标上均优于现有最先进方法,证明了其在处理现实世界视频超分辨率任务中的优越性能和潜力,为未来相关领域的研究和发展提供了新的思路和方向。
STAR主要功能
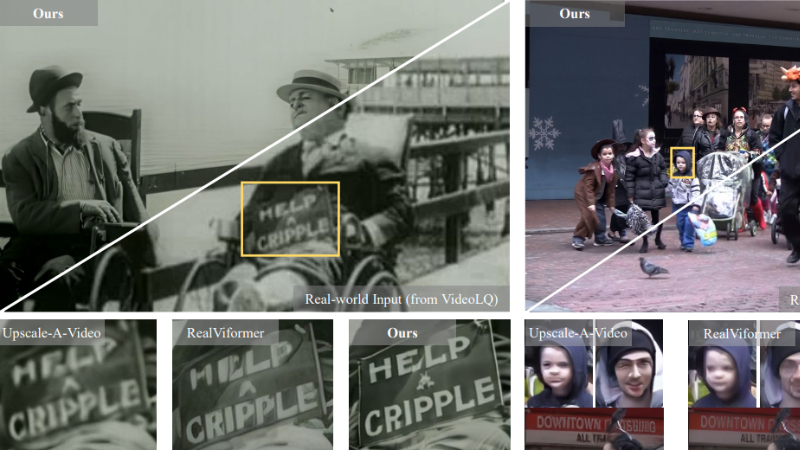
- 现实世界视频超分辨率:STAR能够将低分辨率的现实世界视频恢复成高分辨率版本,同时保留清晰的细节和强时间一致性。
- 去除复杂退化伪影:针对现实世界视频中存在的噪声、模糊和压缩等复杂退化问题,STAR能够有效去除伪影,恢复出更自然、更真实的视频内容。
- 生成逼真细节:STAR能够生成逼真的空间细节,如清晰的面部特征和准确的文本结构,提升视频的视觉质量。
- 保持时间一致性:在视频帧与帧之间,STAR能够保持良好的时间一致性,避免出现跳动或不自然的运动现象,使视频播放更加流畅。
STAR技术原理
- 文本到视频(T2V)扩散模型:STAR利用大规模预训练的T2V扩散模型作为基础,这些模型具备强大的生成能力和时空先验知识,能够从文本描述中生成高质量的视频内容。通过将T2V模型应用于视频超分辨率任务,STAR能够更好地捕捉视频中的时空信息。
- 局部信息增强模块(LIEM):
- 动机:大多数T2V模型主要依赖全局注意力机制,这在处理现实世界视频超分辨率时存在局限性,如难以去除复杂退化和缺乏局部细节。
- 实现:在全局注意力块前引入LIEM,通过平均池化和最大池化提取输入特征的局部信息,再与全局特征结合。这样可以使T2V模型先关注局部区域的退化并进行处理,再聚合全局特征,从而减轻伪影并丰富细节。
- 动态频率(DF)损失:
- 动机:扩散模型在生成过程中可能会牺牲恢复结果的保真度,尤其是在不同频率成分的处理上存在差异。STAR观察到模型在反向扩散过程中先恢复结构(低频),再细化细节(高频)。
- 实现:在每个扩散步骤中,将预测的高分辨率视频转换到频域,分离出低频和高频成分,并分别计算与真实视频的差异。通过设计权重函数,使模型在早期阶段更关注低频成分的恢复,在后期阶段更关注高频成分的恢复,从而提高整体保真度。
STAR应用场景
- 视频监控:将低分辨率的监控视频恢复成高分辨率版本,清晰呈现监控对象的面部特征、车牌号码等细节信息,有助于提高安防监控的准确性和可靠性。
- 影视后期制作:对老旧或低质量的影视素材进行超分辨率处理,提升画面质量,使其达到现代高清影视标准,延长影视作品的生命周期。
- 视频会议:改善视频会议中的低分辨率视频质量,使参会人员的面部表情、肢体动作等细节更加清晰,增强远程沟通的互动性和沉浸感。
- 体育赛事转播:对体育赛事的低分辨率直播视频进行超分辨率处理,让观众能够更清楚地看到运动员的动作细节和比赛现场的精彩瞬间,提升观赛体验。
- 医疗影像:在医疗影像领域,对低分辨率的医学影像进行超分辨率恢复,有助于医生更准确地观察和分析病变区域的细节,提高诊断的准确性和效率。
- 视频内容创作:为视频创作者提供高质量的视频素材,将低分辨率的视频片段恢复成高分辨率版本,满足高清视频创作的需求,提升作品的视觉效果和专业度。
STAR项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号