SVFR:从低质量的视频中恢复出高质量的人脸图像
SVFR简介
SVFR(Stable Video Face Restoration)是由中国厦门大学多媒体可信感知与高效计算教育部重点实验室与腾讯优图实验室联合开发的统一框架,旨在解决视频中的人脸恢复问题。该框架整合了视频人脸恢复(BFR)、人脸修复(inpainting)和人脸着色(colorization)任务,通过共享表示来增强有限训练数据的监督,并提高整体恢复质量。SVFR基于预训练的Stable Video Diffusion(SVD)模型,利用其时间稳定的建模能力,并通过任务嵌入和统一潜在正则化等创新模块,实现了不同任务间的信息整合与特征共享。此外,SVFR还引入了面部先验学习目标和自引用细化策略,进一步提升了恢复视频的保真度和时间稳定性,为视频人脸恢复领域提供了新的技术范式。
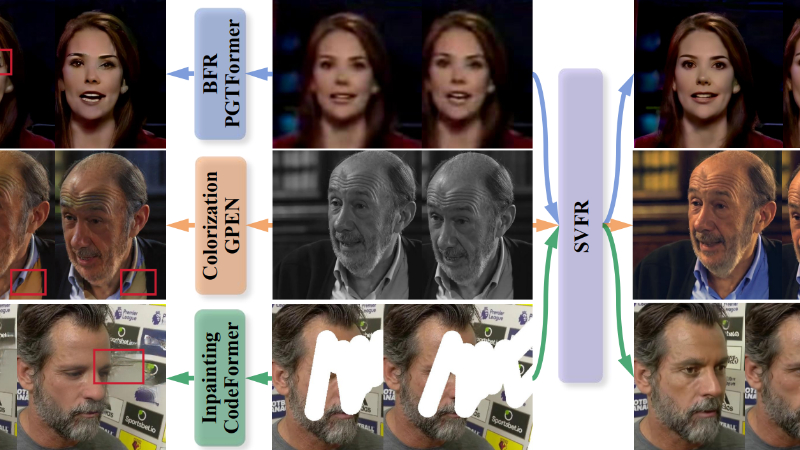
SVFR主要功能
-
视频人脸恢复(BFR):从低质量的视频中恢复出高质量的人脸图像,改善分辨率、减少噪声和模糊,同时保持人脸的身份一致性。
-
人脸修复(Inpainting):填补视频中人脸区域的缺失或损坏部分,如遮挡物覆盖的区域,恢复完整的人脸结构。
-
人脸着色(Colorization):为灰度视频添加自然的颜色,使视频看起来更加生动和真实,同时保持颜色的一致性和自然性。
-
时间稳定性增强:确保恢复后的视频在时间序列上具有连贯性和稳定性,减少帧与帧之间的抖动和不连续性,提高视频的整体流畅度。
SVFR技术原理
-
统一人脸恢复框架:
-
任务嵌入(Task Embedding):通过二进制指示器表示不同任务,模型通过任务嵌入层将这些指示器映射到任务嵌入中,以指导模型适应特定任务,增强模型对不同任务的识别和适应能力。
-
统一潜在正则化(ULR):通过计算中间层的输出特征之间的对比损失,ULR提高了不同任务之间的视觉一致性,并加强了恢复质量,确保不同任务的输出帧在恢复过程中共享统一的中间特征,增强结构一致性,减少伪影,提高整体生成质量。
-
-
面部先验学习:
-
地标预测器(Landmark Predictor):利用从U-Net中间层输出的特征,通过地标预测器估计68个人脸地标点,这些地标点用于引导模型关注与人脸结构相关的信息,提高面部特征对齐的准确性。
-
面部先验损失(Facial Prior Loss):通过特定的损失函数,模型被引导关注人脸结构相关的信息,确保在不同任务中保持面部结构的一致性,提高模型的稳定性和鲁棒性。
-
-
自引用细化策略:
-
参考帧注入:在训练阶段,模型以50%的dropout率使用参考帧,将参考帧的特征注入到U-Net模型的初始噪声中,同时提取身份特征并注入到U-Net的交叉注意力层中,提高模型的泛化能力。
-
序列生成:在推理阶段,模型首先生成初始视频段,然后选择一帧作为后续段的参考,确保整个视频序列的风格和结构连续性,提高长视频序列的稳定性和连贯性。
-
-
预训练的Stable Video Diffusion(SVD)模型:
-
时间稳定的建模能力:SVD模型通过引入3D卷积层和时间注意力层,处理时间数据,确保视频在时间维度上的稳定性。
-
潜在空间编码:将视频的每一帧编码到潜在空间中,通过前向和反向过程进行噪声添加和去除,最终生成高质量的视频。
-
SVFR应用场景
-
视频会议:提升低质量视频会议的画质,减少网络传输中的压缩伪影,使参会者的人脸更加清晰自然。
-
老电影修复:恢复老电影中因年代久远而退化的画面质量,增强色彩和细节,让经典影片重现昔日光彩。
-
监控视频增强:改善监控视频的画质,特别是在夜间或低光照条件下,提高人脸的可识别度,助力安防监控。
-
社交媒体视频:优化用户上传的低质量视频,提升视频的视觉效果,增强用户体验。
-
视频直播:实时增强直播视频的画质,特别是在网络条件不佳时,保持直播画面的稳定性和清晰度。
-
医疗影像处理:在医疗视频影像中,如内窥镜视频,提升图像质量,帮助医生更准确地进行诊断。
SVFR项目入口
- 项目主页:https://wangzhiyaoo.github.io/SVFR/
- GitHub代码库:https://github.com/wangzhiyaoo/SVFR
- arXiv研究论文:https://arxiv.org/pdf/2501.01235
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号