MiniMax-01:MiniMax推出的全新系列模型
MiniMax-01简介
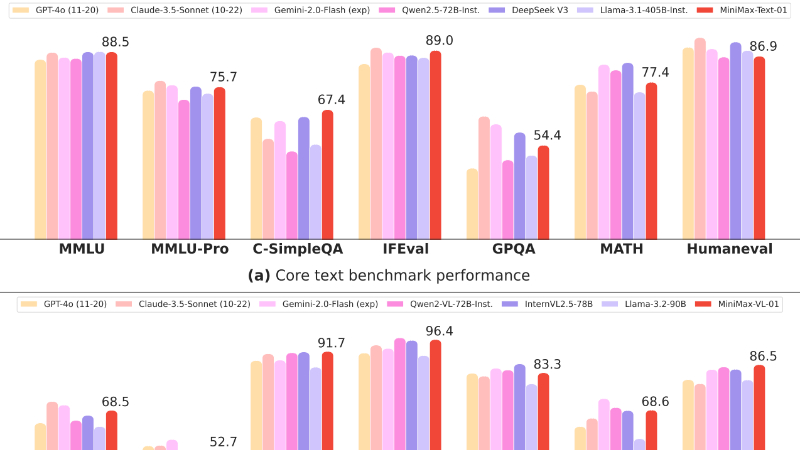
MiniMax-01是MiniMax推出的全新系列模型,旨在突破大型语言模型(LLMs)和视觉语言模型(VLMs)在处理长文本上下文时的限制。该系列包括MiniMax-Text-01和MiniMax-VL-01两个模型,它们通过独特的闪电注意力机制和混合专家(MoE)架构,实现了对长达400万tokens上下文的有效处理。MiniMax-Text-01在训练时能够处理高达100万tokens的上下文窗口,并在推理时扩展至400万tokens,显著超越了现有模型的能力。MiniMax-VL-01则进一步集成了视觉理解能力,通过视觉编码器和适配器,使模型能够理解和生成与图像相关的内容。这两个模型不仅在标准学术基准测试中表现出色,还在实际应用中展现出卓越的性能,特别是在长上下文处理和视觉语言理解方面。MiniMax-01系列的开源和API发布,为研究人员和开发者提供了宝贵的资源,推动了人工智能技术的进一步发展。
MiniMax-01主要功能
-
长文本处理:MiniMax-01系列模型能够处理长达400万tokens的上下文窗口,显著提升了模型在长文本理解和生成任务中的表现。
-
多任务处理:支持多种任务类型,包括知识问答、复杂推理、数学、编码和视觉语言理解等。
-
视觉语言理解:MiniMax-VL-01通过集成视觉编码器,能够处理和生成与图像相关的内容,适用于视觉问答、图像描述等任务。
-
高效推理:通过优化的架构和计算策略,MiniMax-01系列模型在推理时具有较低的延迟和高效的性能。
-
开源与API支持:提供开源模型和API接口,方便研究人员和开发者进行二次开发和应用。
MiniMax-01技术原理
-
闪电注意力机制(Lightning Attention):采用线性注意力的变体,通过“右乘积核技巧”将传统Transformer的二次计算复杂度降低到线性复杂度,显著提升了长序列处理的效率。
-
混合专家(MoE)架构:通过多个前馈网络(FFNs)来增强模型的可扩展性和效率,每个token激活459亿参数,实现了高效的参数和计算能力利用。
-
分布式训练与推理优化:采用基于令牌分组的重叠方案、数据打包技术和Varlen Ring Attention算法,减少了计算和通信开销,提升了训练和推理效率。
-
多阶段训练策略:包括预训练、监督微调(SFT)和离线/在线强化学习(RL)阶段,通过多样化的高质量数据集和层次化奖励系统,提升模型的通用性能和实际应用能力。
-
视觉编码器集成:MiniMax-VL-01通过Vision Transformer(ViT)和MLP投影器,将图像特征与文本特征结合,实现了视觉语言理解任务的支持。
-
高效内核融合与推理优化:通过批量内核融合、分离预填充和解码执行、多级填充和strided batched matmul扩展等策略,提高了推理效率,降低了延迟。
MiniMax-01应用场景
-
长文本生成与总结:能够生成和总结长篇幅的文档,如学术论文、报告和书籍,帮助用户快速理解和提取关键信息。
-
复杂问答系统:处理涉及多个领域和长上下文的复杂问题,提供准确和详细的答案,适用于智能客服和知识管理系统。
-
创意写作与内容生成:生成创意故事、诗歌、歌词等,为作家、编剧和内容创作者提供灵感和素材。
-
代码生成与辅助编程:自动生成代码片段和程序,帮助开发者快速实现功能,提高编程效率。
-
视觉问答与图像描述:理解和生成与图像相关的内容,如图像描述、视觉问答和图像标注,适用于视觉内容管理和智能图像搜索。
-
多模态学习与教育:结合文本和图像进行教学,提供丰富的学习材料和互动体验,适用于在线教育平台和智能教育工具。
MiniMax-01项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号