ParGo:字节跳动联合中山大学推出的多模态大模型连接器
ParGo简介
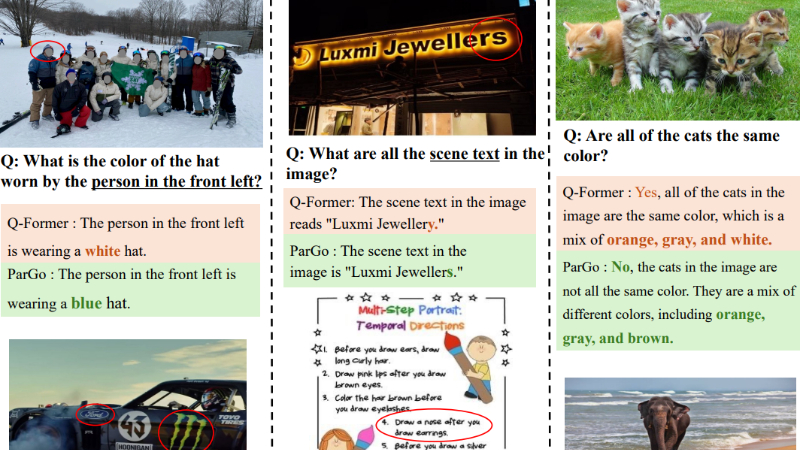
ParGo是由中山大学计算机科学与工程学院和字节跳动中国团队共同开发的一种新型Partial-Global投影器,旨在连接视觉和语言模态,以增强多模态大型语言模型(MLLMs)的能力。它通过整合全局和局部视图,有效地弥合了独立预训练的视觉编码器和大型语言模型(LLMs)之间的表示差距,特别强调了细节感知能力的重要性。为了有效训练ParGo,开发团队还收集了一个名为ParGoCap-1M-PT的大规模详细描述图像-文本数据集,包含100万张图像及其高质量的详细描述。ParGo在多个MLLM基准测试中表现出色,特别是在需要细节感知能力的任务中,显著优于其他投影器。
ParGo主要功能
-
连接视觉和语言模态:ParGo作为多模态大型语言模型(MLLMs)中的一个关键组件,能够有效地将视觉特征和语言特征进行对齐,使模型能够更好地理解和生成与图像相关联的文本内容。
-
整合全局和局部视图:通过同时提取图像的全局信息和局部细节信息,ParGo能够提供更全面的视觉特征表示,从而提升模型在各种任务中的性能,尤其是在需要细节感知能力的任务中。
-
提升模型性能:在多个MLLM基准测试中,ParGo相较于其他投影器表现出显著的性能优势,特别是在视觉问答、图像描述生成等任务中,能够更准确地理解和生成与图像相关的内容。
-
数据集构建:为了更好地训练ParGo,开发团队构建了一个大规模的详细描述图像-文本数据集ParGoCap-1M-PT,包含100万张图像及其高质量的详细描述,有助于模型学习更丰富的视觉和语言特征对齐。
ParGo技术原理
-
Partial-Global Perception block:
-
全局标记和局部标记:ParGo使用两种类型的可学习标记——全局标记和局部标记。全局标记与图像的所有视觉特征进行交互,以提取全局信息;局部标记仅与图像的部分视觉特征交互,以提取局部细节信息。
-
预定义注意力掩码:通过预定义的注意力掩码,确保每个局部标记只与图像的一部分特征交互,而全局标记与所有特征交互。这种设计使得模型能够同时关注图像的整体和局部细节。
-
交叉注意力层:全局标记和局部标记通过交叉注意力层与图像特征进行交互,从而提取出更丰富的视觉特征表示。
-
-
Cascaded Partial Perception block:
-
掩码自注意力块:为了考虑图像中不同局部区域之间的关系,ParGo引入了Cascaded Partial Perception (CPP) 块。CPP块使用掩码自注意力机制,使得不同层的局部标记之间能够进行交互。
-
逐层增加可见标记:随着层数的增加,每个局部标记可见的相邻标记数量线性增加。这种设计使得模型能够逐步扩大局部标记的感知范围,从而更好地理解图像中不同局部区域之间的关系。
-
-
大规模详细描述数据集:
-
数据收集:ParGoCap-1M-PT数据集通过从Laion数据集中随机选择大量图像,并使用强大的闭源MLLMs(如GPT4-V和Gemini)生成详细描述来构建。这些描述不仅包含图像的全局信息,还包含多个局部区域的详细信息。
-
质量控制:为了确保生成的描述质量,开发团队使用多个模型计算图像和生成描述之间的相似度,过滤掉相似度低的图像-描述对,从而保证数据的高质量。
-
-
两阶段训练流程:
-
预训练阶段:在预训练阶段,冻结视觉编码器和大型语言模型(LLM),专注于训练Partial-Global投影器,以更好地对齐视觉和语言模态。
-
监督微调阶段:在监督微调阶段,保持视觉编码器冻结,对Partial-Global投影器和LLM进行微调。使用参数高效的微调策略Low-Rank Adaptation (LoRA),以提高训练效率。
-
ParGo应用场景
-
视觉问答:用户可以向模型提出关于图像的问题,ParGo能够准确理解图像内容并生成准确的答案。例如,用户问“图中有多少只猫?”ParGo可以准确计数并回答。
-
图像描述生成:ParGo可以生成详细且准确的图像描述,不仅包含图像的全局信息,还能捕捉局部细节。例如,对于一张包含多个物体和场景的复杂图像,ParGo能够生成包含所有重要信息的描述。
-
图像内容理解:在需要理解图像内容的场景中,ParGo能够提供丰富的视觉特征,帮助模型更好地理解图像中的物体、场景和事件。例如,识别图像中的特定物体或场景,并生成相关的描述。
-
文档理解:ParGo可以用于理解包含文本和图像的文档,如发票、合同等。它能够识别文档中的文本内容,并结合图像信息生成准确的描述和理解。例如,识别发票中的金额、日期等信息。
-
多模态搜索:
在多模态搜索中,用户可以通过图像和文本查询来搜索相关信息。ParGo能够将图像和文本特征进行对齐,提高搜索的准确性和相关性。例如,用户上传一张产品图片并输入相关描述,ParGo可以帮助找到类似的产品。
-
智能助手:ParGo可以集成到智能助手中,使其能够更好地理解和生成与图像相关的内容。例如,用户向智能助手展示一张照片并询问照片中的内容,ParGo能够生成详细的描述并回答用户的问题。
ParGo项目入口
- Github代码库:https://github.com/bytedance/ParGo
- arXiv技术论文:https://arxiv.org/pdf/2408.12928
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号