Mini-InternVL简介
Mini-InternVL是由上海人工智能实验室、清华大学、南京大学、复旦大学、香港中文大学、商汤科技研究部和上海交通大学等机构联合开发的轻量级多模态大型语言模型系列。该模型参数规模在1B到4B之间,仅用5%的参数就实现了与大型模型90%相当的性能,极大地提高了模型的效率和实用性。开发团队通过知识蒸馏技术,使Mini-InternVL在视觉编码器上继承了更强大模型的能力,并提出了统一的迁移学习框架,让模型能够轻松适应自动驾驶、医学图像、遥感等多个特定领域的下游任务,为多模态大型语言模型的广泛应用提供了有力支持。
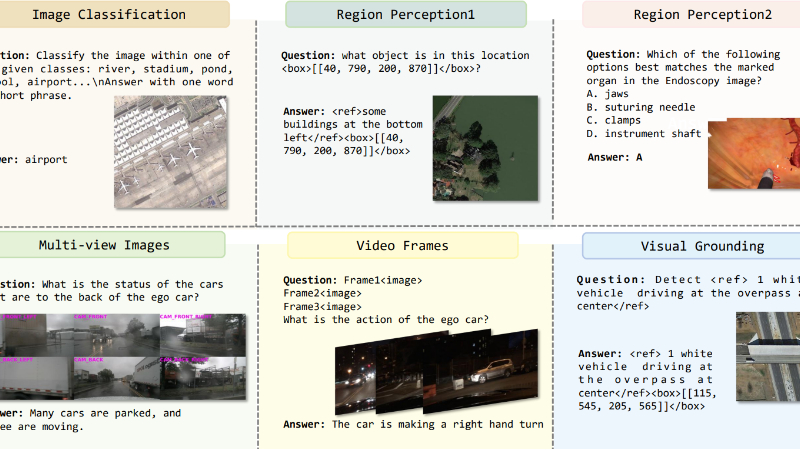
Mini-InternVL主要功能
-
高效的多模态处理:
-
Mini-InternVL能够处理视觉和语言两种模态的数据,支持图像-文本对齐、图像描述生成、视觉问答等任务。
-
在多个通用多模态基准测试中表现出色,如MMBench、ChartQA、DocVQA和MathVista。
-
-
轻量级设计:
-
参数规模在1B到4B之间,仅用5%的参数就实现了与大型模型90%相当的性能,显著减少了计算资源需求。
-
适用于消费级GPU或边缘设备,降低了部署成本。
-
-
领域适应能力:
-
提供统一的迁移学习框架,能够高效适应多个特定领域的下游任务,如自动驾驶、医学图像问答和遥感。
-
在这些领域中,Mini-InternVL能够与其他领域特定方法相当的性能。
-
Mini-InternVL技术原理
-
知识蒸馏:
-
使用InternViT-6B作为教师模型,通过知识蒸馏技术将其视觉编码能力传递给轻量级的InternViT-300M。
-
这种方法使得Mini-InternVL能够在保持高效的同时,继承强大的视觉表示能力。
-
-
视觉编码器:
-
采用InternViT-300M作为视觉编码器,通过知识蒸馏从更强大的视觉模型中继承知识。
-
视觉编码器能够处理多样化的图像数据,包括自然图像、OCR图像、图表和跨学科图像。
-
-
统一的迁移学习框架:
-
提出了一种简单而有效的迁移学习框架,标准化了模型架构、数据格式和训练策略,使模型能够高效适应不同领域的下游任务。
-
通过将不同领域的任务格式化为视觉问答(VQA)和对话格式,简化了模型的迁移过程。
-
-
动态分辨率输入策略:
-
采用动态分辨率输入策略,增强了模型捕捉细节的能力。
-
通过像素反向操作减少视觉token数量,提高了图像处理效率。
-
-
全参数微调:
-
在领域适应阶段,进行全参数微调,以确保模型在特定领域的最佳性能。
-
在训练过程中,加入一定比例的通用多模态数据,以保持模型的通用能力和泛化能力。
-
Mini-InternVL应用场景
-
自动驾驶:
-
感知与预测:处理多视角图像,识别道路标志、车辆、行人等对象,预测其行为和运动轨迹。
-
路径规划:根据环境信息生成安全、高效的行驶路径,辅助自动驾驶系统的决策。
-
-
医学图像分析:
-
疾病诊断:分析X光、CT、MRI等医学图像,辅助医生进行疾病诊断,如肺炎、肿瘤等。
-
病理分析:处理病理切片图像,识别细胞异常,辅助病理学家进行诊断。
-
-
遥感图像处理:
-
环境监测:分析卫星和航空遥感图像,监测森林火灾、洪水、土地利用变化等。
-
目标识别:识别和分类遥感图像中的建筑物、道路、农田等目标,支持城市规划和资源管理。
-
-
文档理解:
-
文档问答:处理文档图像,回答与文档内容相关的问题,如提取关键信息、解释图表等。
-
表格理解:解析表格数据,提取和分析表格中的信息,支持财务分析和数据处理。
-
-
图像描述生成:
-
内容描述:生成图像的自然语言描述,帮助视障人士理解图像内容。
-
社交媒体:自动生成图像描述,增强社交媒体内容的吸引力和可访问性。
-
-
视觉问答:
-
教育辅助:回答学生关于图像内容的问题,如解释科学图表、历史照片等。
-
智能客服:处理用户上传的图像,回答与产品、服务相关的问题,提升客户体验。
-
Mini-InternVL项目入口
- GitHub代码库:https://github.com/OpenGVLab/InternVL
- HuggingFace:https://huggingface.co/collections/OpenGVLab/internvl-adaptation
- arXiv技术论文:https://arxiv.org/pdf/2410.16261
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号