VideoWorld:字节联合北京交通大学等推出的视频生成模型
VideoWorld简介
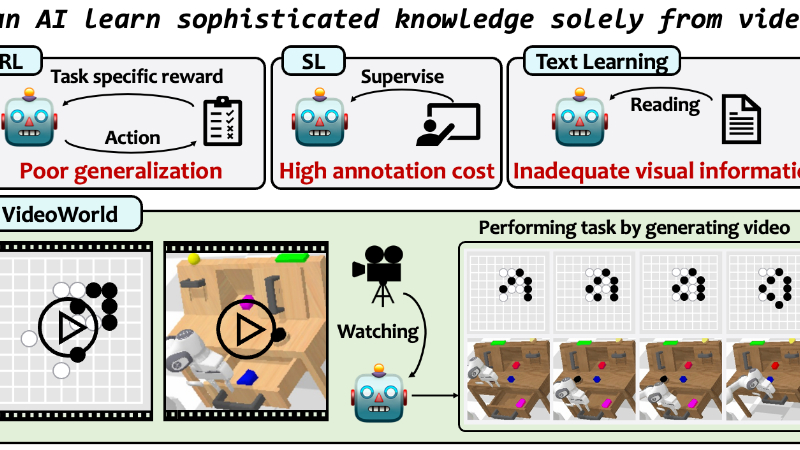
VideoWorld是由北京交通大学、中国科学技术大学和字节跳动种子团队共同开发的自回归视频生成模型,旨在探索深度生成模型是否能够仅通过无标签视频数据学习复杂知识。该模型通过观察视频序列,学习任务规则、推理和规划能力,无需依赖语言指令或标注数据。开发团队提出了潜在动态模型(LDM)作为关键组件,以提高学习效率和效果。在围棋和机器人控制任务中,VideoWorld展现出强大的知识获取能力,达到了专业水平的围棋对弈能力,并在机器人任务中实现了跨环境的泛化。这一研究为从视觉数据中获取知识开辟了新途径,所有代码、数据和模型均已开源,为未来研究提供了坚实基础。
VideoWorld主要功能
-
从无标签视频中学习复杂知识:VideoWorld能够仅通过观察无标签的视频数据,学习任务的规则、推理和规划能力,无需依赖语言指令或人工标注。
-
高效的知识获取与泛化:该模型通过紧凑的视觉变化表征,显著提高了学习效率,并在不同任务和环境中展现出强大的泛化能力。
-
支持多种任务类型:VideoWorld在围棋和机器人控制任务中表现出色,能够学习并执行复杂的策略和操作,接近人类专业水平。
-
自动生成任务相关的操作:模型通过生成视频帧和潜在代码,推断出任务所需的操作(如围棋的落子或机器人的动作),无需显式动作标签。
-
提供知识学习的可视化与分析:通过潜在动态模型(LDM),VideoWorld能够可视化学习到的模式和策略,为研究知识获取过程提供支持。
VideoWorld技术原理
-
自回归视频生成框架:VideoWorld基于自回归视频生成模型,结合VQ-VAE(矢量量化-变分自编码器)和Transformer架构。VQ-VAE将视频帧转换为离散标记,Transformer则通过预测下一帧标记进行训练。
-
潜在动态模型(LDM):LDM是VideoWorld的核心组件,通过查询嵌入捕捉多帧之间的视觉变化,并将其压缩为一组潜在代码。这些代码作为紧凑的视觉上下文表示,帮助模型更高效地学习和推理。
-
紧凑的视觉变化表征:视频数据中包含大量冗余信息,LDM通过提取与任务相关的视觉变化,减少冗余,提高学习效率。例如,在围棋中,LDM能够将多步棋盘变化压缩为紧凑的潜在代码。
-
多步预测与推理:VideoWorld在训练时同时预测视频帧和潜在代码,使模型能够更好地捕捉长期依赖关系和动态变化。这种机制支持模型进行多步推理和规划。
-
逆动力学模型(IDM):IDM用于将生成的视频帧和潜在代码转换为具体的任务操作(如机器人的控制信号)。通过少量标注数据训练,IDM能够从模型生成的内容中推断出合理的动作。
-
无监督学习与泛化能力:VideoWorld完全依赖无标签视频数据进行训练,避免了对大量标注数据的依赖。这种无监督学习方式使模型能够泛化到未见过的任务和环境中,展现出强大的适应性。
VideoWorld应用场景
-
机器人控制与操作:VideoWorld可以用于机器人任务规划和控制,例如在复杂环境中完成物体抓取、搬运和操作,无需依赖大量标注数据。
-
智能游戏开发:在棋类游戏(如围棋、国际象棋)中,VideoWorld能够学习游戏规则和策略,开发智能对手或辅助玩家进行策略分析。
-
自动驾驶仿真:通过从交通场景视频中学习,VideoWorld可用于自动驾驶系统的仿真和测试,帮助预测交通动态和规划驾驶决策。
-
工业自动化:在工业生产中,VideoWorld能够学习设备操作流程和故障检测模式,实现自动化监控和质量控制。
-
虚拟现实与增强现实:VideoWorld可以生成逼真的虚拟场景和交互,为VR/AR应用提供更自然的用户体验,例如虚拟训练环境或教育工具。
-
智能安防监控:在安防领域,VideoWorld能够从监控视频中学习异常行为模式,实现自动检测和预警,提高安全性和效率。
VideoWorld项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号