DITTO-2:Adobe联合加州大学推出的可控音乐生成模型
DITTO-2简介
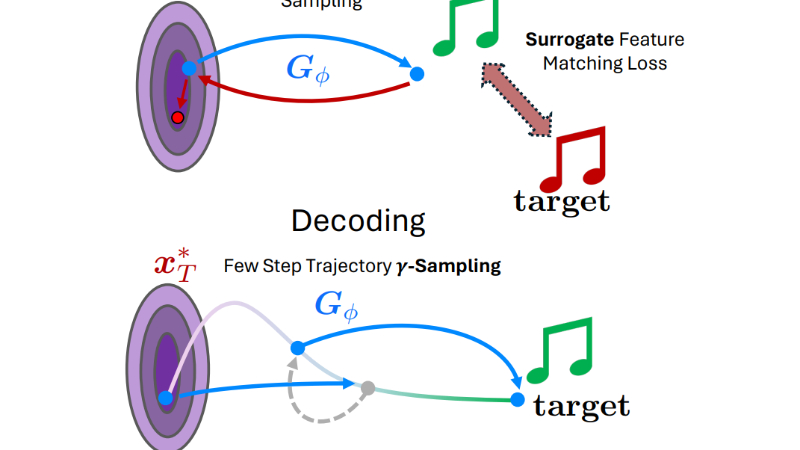
DITTO-2 是由加州大学圣地亚哥分校和 Adobe Research 联合开发的一种新型可控音乐生成模型。该技术旨在通过加速扩散模型的推理时间优化(ITO)过程,实现快速、高质量且可控的音乐生成。DITTO-2 通过改进扩散模型的蒸馏和优化策略,将生成速度提升至超过实时水平,同时显著改善了控制精度和音频质量。开发团队通过一致性模型(CM)和一致性轨迹模型(CTM)的蒸馏技术,以及替代优化策略,大幅减少了计算成本,使得 DITTO-2 在多个音乐生成任务上表现出色,包括强度控制、旋律控制和音乐结构控制等。此外,DITTO-2 还能够将无条件扩散模型转换为具有文本控制能力的模型,为实时交互式音乐创作和文本到音乐生成提供了新的可能性。
DITTO-2主要功能
-
快速音乐生成:DITTO-2 能够在比实时快的速度下生成音乐,适用于多种应用场景,如音乐填充(inpainting)、扩展(outpainting)、强度控制、旋律控制和音乐结构控制等。
-
高质量生成:通过改进的扩散模型蒸馏和优化策略,DITTO-2 在保持生成速度的同时,显著提高了生成音乐的音频质量。
-
精确控制:DITTO-2 提供了对音乐生成过程的精细控制,包括对旋律、强度和音乐结构的控制,满足创作者对音乐细节的需求。
-
文本到音乐生成:DITTO-2 能够将无条件扩散模型转换为具有文本控制能力的模型,实现文本到音乐的生成,增强了模型的适用性和灵活性。
DITTO-2技术原理
-
扩散模型蒸馏(Diffusion Distillation):
-
使用一致性模型(CM)或一致性轨迹模型(CTM)对预训练的扩散模型进行蒸馏。
-
蒸馏后的模型能够在单步采样中快速生成音乐,同时保持高质量。
-
CM 和 CTM 的蒸馏过程被优化以适应推理时间优化(ITO)方法,减少了采样步骤,同时避免了传统扩散模型在少步采样时的质量下降。
-
-
替代优化(Surrogate Optimization):
-
将 ITO 过程分为优化阶段和解码阶段。
-
优化阶段使用蒸馏后的模型进行单步采样,以快速估计初始噪声潜变量。
-
解码阶段使用多步采样生成高质量的最终音乐输出。
-
替代优化目标允许在优化过程中使用高效的单步采样,同时在解码阶段利用多步采样提升质量。
-
-
推理时间优化(Inference-Time Optimization, ITO):
-
通过优化初始噪声潜变量来实现对生成音乐的控制。
-
定义可微分的特征提取函数(如旋律提取、强度控制等)和匹配损失函数,优化潜变量以达到目标风格。
-
DITTO-2 在优化过程中引入了更高效的蒸馏模型,显著减少了优化时间和计算成本。
-
-
自适应采样策略:
-
根据优化步骤动态调整采样步数,例如在优化初期使用单步采样,后期逐步增加采样步数。
-
这种策略在不显著增加运行时间的情况下,进一步提升了生成音乐的质量和控制精度。
-
-
文本相似性控制:
-
利用 CLAP(Contrastive Language-Audio Pretraining)模型提取音频和文本的嵌入向量。
-
通过优化生成音乐的 CLAP 嵌入向量与目标文本嵌入向量的相似性,实现高质量的文本到音乐生成。
-
该技术使得无条件扩散模型能够生成与文本描述高度相关的音乐,无需额外的音乐-文本对训练数据。
-
DITTO-2应用场景
DITTO-2项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号