EMO2:阿里推出的音频驱动虚拟形象视频生成技术
EMO2简介
EMO2是由阿里巴巴集团智能计算研究所开发的一种新型音频驱动虚拟形象视频生成技术。该方法通过创新的两阶段框架,实现了富有表现力的面部表情和手势的同步生成。开发团队重新定义了音频与人体动作的关联方式,将手部动作视为“末端执行器”,利用其与音频的强相关性简化生成任务。第一阶段直接从音频生成手部姿态,第二阶段则借助扩散模型将手部动作融入视频帧合成中,生成连贯自然的全身动作。EMO²在视觉质量和同步准确性上超越了现有技术,为音频驱动的虚拟形象动画提供了新的思路和解决方案。
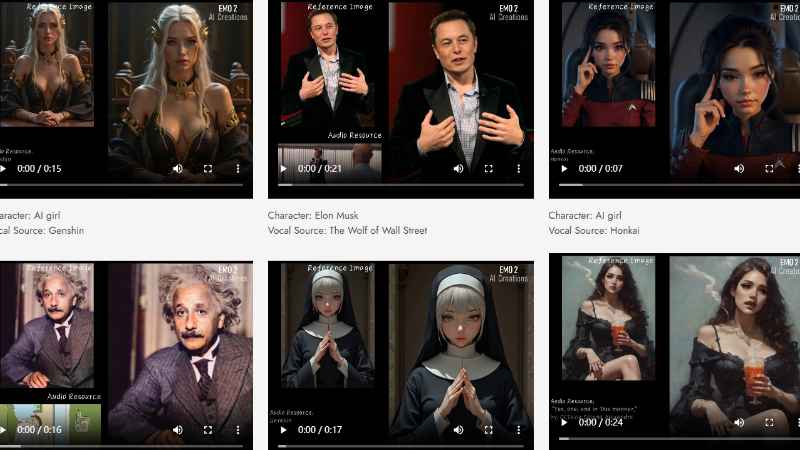
EMO2主要功能
-
音频驱动的虚拟形象动画生成:EMO2能够从输入的音频信号(如语音或音乐)生成与之同步的虚拟形象视频,包含丰富的面部表情和手势动作。
-
手部动作与全身动作的同步生成:该方法专注于生成与音频高度相关的手部动作,并利用这些动作驱动全身运动,生成自然流畅的全身动画。
-
多样化与个性化动作生成:EMO2支持不同风格(如演讲、唱歌、手势舞)和速度的动作生成,同时能够根据输入的参考图像调整动作,以适应不同的场景和角色。
-
高质量视频合成:通过先进的扩散模型技术,EMO²能够生成高分辨率、高质量的视频帧,同时保持身份一致性(如面部特征)和动作连贯性。
-
实时同步与表现力增强:该技术能够实时将音频信号转化为视觉动作,增强虚拟形象的表现力和生动性,适用于虚拟主播、动画制作等领域。
EMO2技术原理
-
两阶段生成框架
-
第一阶段:手部动作生成
利用音频信号直接生成手部姿态,基于手部动作与音频的强相关性,通过扩散模型(如Diffusion Transformer)提取音频特征并映射为手部运动参数。 -
第二阶段:视频帧合成
使用扩散模型结合第一阶段生成的手部动作,合成包含面部表情和全身动作的视频帧。通过ReferenceNet等技术,将参考图像特征与生成动作融合,确保视频的自然性和一致性。
-
-
扩散模型的应用
基于扩散模型(Diffusion Model)的逆向去噪过程,将噪声数据逐步还原为清晰的图像或动作序列。该模型通过引入音频特征和手部动作作为控制信号,实现对生成内容的精确引导。 -
像素先验逆运动学(Pixels Prior IK)
通过仅生成手部动作,利用视频生成模型中隐含的人体逆运动学先验知识,推导出全身动作,从而简化生成任务并提高动作的自然性。 -
多模态融合与控制
结合音频特征、手部动作、关键点信息以及参考图像特征,通过交叉注意力机制和置信度嵌入等技术,增强生成动作的多样性和准确性。 -
姿态判别器与优化
在训练过程中引入姿态判别器,预测生成动作的关键点和肢体热图,优化生成模型以提高动作的自然性和结构准确性。
EMO2应用场景
-
虚拟主播:用于新闻播报、直播带货或互动节目,根据语音内容实时生成自然的表情和手势,增强观众的观看体验。
-
虚拟客服:在在线客服场景中,虚拟形象可以根据语音对话生成相应表情和动作,提供更生动、友好的客户服务。
-
动画制作:为动画电影或短视频快速生成与音频同步的角色动画,降低制作成本,提高创作效率。
-
在线教育:在教育视频中,虚拟教师可以根据讲解内容生成生动的手势和表情,使教学内容更加生动易懂。
-
游戏开发:为游戏角色生成实时动作和表情,增强游戏的沉浸感和交互性,尤其适用于角色扮演和虚拟现实游戏。
-
社交媒体与娱乐:用户可以上传自己的照片和语音,生成个性化的虚拟形象视频,用于社交媒体分享或娱乐内容创作。
EMO2项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号