VARGPT简介
VARGPT是由北京大学计算机学院的研究团队开发的一种新型多模态大型语言模型。它通过创新性地扩展LLaVA架构,将视觉理解和生成任务统一在一个自回归框架内,能够高效地处理混合模态的输入和输出。VARGPT在多个视觉中心基准测试中表现出色,显著优于LLaVA-1.5等现有模型,尤其在视觉问答和推理任务中展现了卓越的能力。此外,它还具备出色的指令到图像合成能力,能够根据用户指令生成高质量的图像。VARGPT的开发为多模态AI领域提供了新的探索方向,推动了视觉与语言模型的融合与发展。
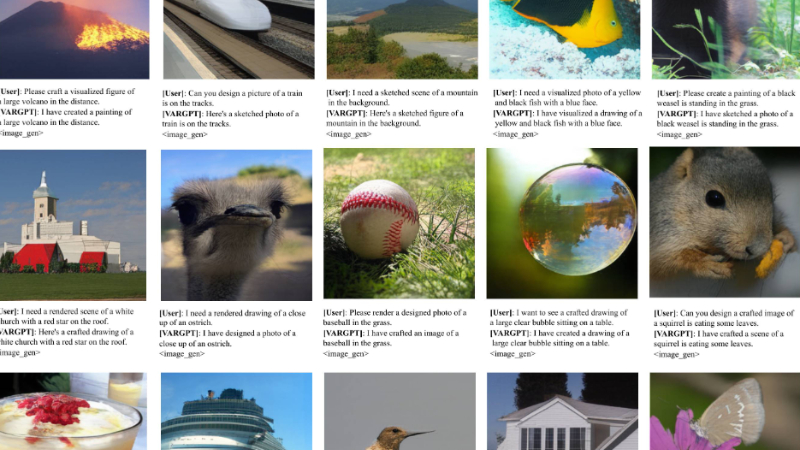
VARGPT主要功能
-
视觉理解:
-
能够准确理解图像内容,并回答与图像相关的复杂问题,例如视觉问答(VQA)任务。
-
支持多模态输入,可以结合文本和图像进行综合理解。
-
-
视觉生成:
-
根据用户输入的文本指令生成高质量的图像,支持指令到图像的合成。
-
支持混合模态输出,可以在对话中同时生成文本和图像。
-
-
多模态对话:
-
支持多轮对话,能够根据上下文理解用户的意图并生成合适的回答。
-
在对话中自然地切换文本和图像生成任务,提供丰富的交互体验。
-
VARGPT技术原理
-
模型架构:
-
视觉理解部分:基于LLaVA-1.5架构,使用Vicuna-7B-v1.5作为语言模型(LLM),并结合CLIP的视觉编码器,通过预测下一个token实现视觉理解和问答。
-
视觉生成部分:引入视觉解码器和两个视觉特征投影器,用于将生成的视觉特征与文本特征进行相互映射。通过预测下一个尺度的token实现视觉生成。
-
混合模态处理:支持同时输出文本和图像模态数据,通过特殊标记(如
<image_gen>)区分文本生成和图像合成的token。
-
-
训练方法:
-
三阶段训练:
-
预训练阶段:使用ImageNet数据集进行预训练,学习文本和视觉空间之间的特征映射。
-
第一阶段指令微调(SFT):使用多轮对话和理解数据集进行训练,增强模型的多轮对话、视觉理解和问答能力。
-
第二阶段指令微调(SFT):专注于提高模型的指令到图像生成能力,通过监督微调来优化视觉解码器和视觉生成投影器。
-
-
-
数据集:
-
预训练数据:1.28M单轮对话样本,用于学习类别和图像之间的对应关系。
-
混合指令微调数据:1.18M样本,包括LLaVA-1.5、LLaVA-OneVision和ImageNet-Instruct-130K的数据。
-
视觉生成指令微调数据:1.4M样本,用于提高模型的指令到图像生成能力。
-
-
技术细节:
-
视觉解码器:使用20亿参数的Transformer架构,包含30层,每层30个注意力头,宽度为1920。
-
多尺度Tokenizer:采用多尺度VAE架构,词汇量为4090,训练于OpenImages数据集,空间下采样因子为16×。
-
位置编码:在视觉解码器中引入绝对位置编码,以区分不同尺度的视觉生成token。
-
分类器自由引导(CFG):通过结合条件生成模型和无条件生成模型的分布估计,提高生成图像的质量。
-
VARGPT应用场景
-
内容创作:根据用户输入的文本描述快速生成高质量的图像或插图,辅助设计师、作家和艺术家进行创意构思和内容创作。
-
教育领域:为教育工作者生成与教学内容相关的图像,帮助学生更好地理解和记忆知识,例如生成科学实验示意图或历史场景插画。
-
虚拟助手:作为虚拟助手的一部分,根据用户指令生成图像或解释图像内容,提供更丰富的交互体验,例如描述用户上传的图片内容。
-
游戏开发:根据游戏剧情生成场景、角色或道具的图像,加速游戏设计和开发流程,为游戏开发者提供创意灵感。
-
广告与营销:根据广告文案快速生成符合主题的图像,用于社交媒体广告、海报设计或产品宣传,提高内容的吸引力和传播效果。
-
客户服务:在客服场景中,根据用户问题生成相关的图像说明,帮助用户更直观地理解产品使用方法或解决问题,提升服务体验。
VARGPT项目入口
- 项目主页:https://vargpt-1.github.io/
- GitHub代码库:https://github.com/VARGPT-family/VARGPT
- arXiv技术论文:https://arxiv.org/pdf/2501.12327
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号