SyncAnimation:实时端到端的音频驱动框架
SyncAnimation简介
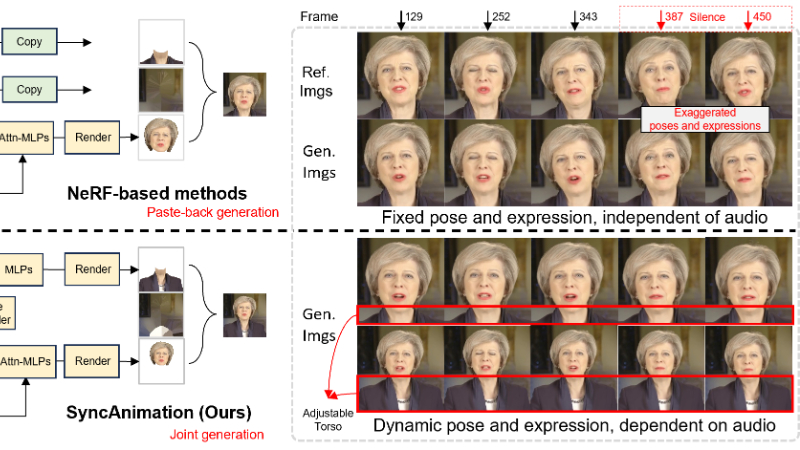
SyncAnimation是由AiShiWeiLai AI Research联合华南理工大学、北京理工大学和北京邮电大学共同开发的实时端到端音频驱动框架。它基于神经辐射场(NeRF),通过音频驱动生成具有真实感和动态变化的人类姿势和面部表情的动画。该框架通过音频到姿势匹配和音频到表情同步,实现了高精度的姿势和表情生成,并确保了头部和上半身的无缝集成以及音频同步的唇部动作。开发团队通过创新的模块化设计,解决了现有方法中音频与头部姿势、表情和上半身动作不一致的问题,使SyncAnimation在实时性和视觉质量方面表现出色,能够满足直播或视频会议等实时场景的需求。
SyncAnimation主要功能
-
音频驱动的虚拟形象生成:SyncAnimation能够通过音频输入生成高精度的虚拟形象,包含面部表情和上半身动作。
-
实时渲染:该框架支持实时生成虚拟形象,适用于直播和视频会议等需要高实时性和视觉质量的场景。
-
高精度姿势和表情生成:通过音频到姿势匹配和音频到表情同步,实现了高精度的头部姿势和面部表情生成。
-
无缝集成:确保头部和上半身的无缝集成,生成的虚拟形象具有高度的连贯性和一致性。
-
多样化的动作生成:支持生成多样化的头部和上半身动作,增强虚拟形象的自然性和真实感。
SyncAnimation技术原理
-
神经辐射场(NeRF):利用NeRF技术,通过音频驱动生成虚拟形象。NeRF能够在3D空间中表示场景,实现高质量的视角合成。
-
AudioPose Syncer:
-
音频感知姿势生成:通过预测欧拉角(roll、pitch、yaw)来生成头部姿势,解决旋转矩阵的正交性和音频与姿势的歧义问题。
-
音频引导的上半身生成:结合音频预测的头部姿势和上半身的可训练坐标,生成动态的上半身动作。
-
-
AudioEmotion Syncer:
-
逼真的表情预测:使用arkit面部混合形状来建模上半脸区域,通过预测相对于平均值的偏差实现眼睛的全闭合。
-
动态头部渲染:利用多个2D哈希编码器生成头部的几何特征,并结合音频特征增强头部动作的预测。
-
-
High-Synchronization Human Renderer:
-
面部感知注意力:通过通道注意力机制,根据哈希编码器的输出获得音频和表情相关的注意力权重,提高渲染质量。
-
精细唇部优化:使用掩码技术降低唇部区域外的注意力权重,并通过LPIPS损失函数优化唇部区域的渲染。
-
-
多阶段训练策略:采用三阶段训练策略,逐步优化音频驱动的上半身生成、与上半身一致的面部生成和唇部细化,确保生成的虚拟形象稳定且逼真。
SyncAnimation应用场景
-
直播与视频会议:实时生成虚拟形象,替代真人出镜,提升互动性和趣味性,同时保护隐私。
-
虚拟客服:创建个性化的虚拟客服形象,提供24小时不间断的客户支持,提升用户体验。
-
在线教育:生成虚拟教师形象,增强教学的趣味性和吸引力,尤其适用于远程教学和在线课程。
-
虚拟主播:用于新闻播报、娱乐节目等,提供更加生动和多样化的视觉效果。
-
社交媒体:用户可以生成个性化的虚拟形象用于社交媒体,增加互动性和个性化表达。
-
游戏与互动娱乐:在游戏中生成玩家的虚拟形象,增强沉浸感和代入感,提升游戏体验。
SyncAnimation项目入口
- 项目主页:https://syncanimation.github.io/
- GitHub代码库:https://github.com/syncanimation
- arXiv技术论文:https://arxiv.org/pdf/2501.14646
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号