R1-V:超低成本强化视觉语言模型的超级泛化能力
R1-V简介
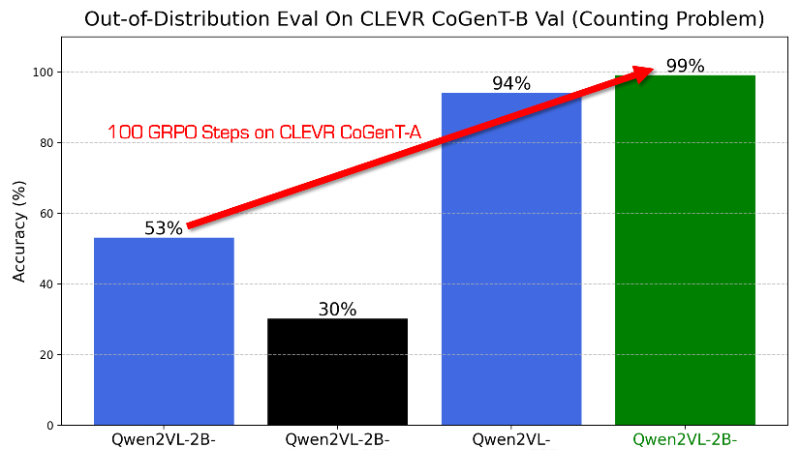
R1-V是一个创新的视觉语言模型(VLM)训练项目,旨在通过强化学习提升模型的泛化能力。它采用可验证奖励的强化学习(RLVR)方法,相比传统的监督微调,在效果和分布外(OOD)鲁棒性上表现更优。在实验中,R1-V通过激励模型学习泛化的视觉计数能力,而非过度拟合训练集,使得2B模型在仅100个训练步骤后,就能在OOD测试中超越72B模型。整个训练过程仅需8块A100 GPU运行30分钟,成本不到3美元。此外,该项目的所有代码、模型和数据集均已开源,为研究人员和开发者提供了一个高效且低成本的VLM训练方案。
R1-V主要功能
-
提升模型泛化能力:通过强化学习方法,让模型具备更强的适应能力,能够更好地处理未见过的、分布外的测试数据。
-
高效低成本训练:仅需少量训练步骤和极低的计算成本,就能显著提升模型性能,适合资源有限的开发者和研究者。
-
多模态融合:能够同时处理图像和文本信息,为复杂的视觉语言任务提供支持。
-
开源与可扩展性:提供完整的开源代码,方便用户根据自己的需求进行修改和扩展。
R1-V应用场景
-
视觉问答:帮助用户通过自然语言提问,模型根据图像内容给出准确回答,可用于教育、智能客服等领域。
-
文档分析:自动解析包含图像和文本的复杂文档,提取关键信息,提高工作效率,适用于金融、法律等行业。
-
图像识别与检测:快速识别图像中的物体或场景,可用于安防监控、自动驾驶等领域。
-
多语言支持:支持多种语言的处理,有助于开发面向国际市场的应用。
-
研究与开发:为研究人员提供一个低成本、高效的实验平台,推动视觉语言模型技术的发展。
R1-V项目入口
- GitHub代码库:https://github.com/Deep-Agent/R1-V
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号