Hibiki:Kyutai推出的实时语音翻译模型
Hibiki简介
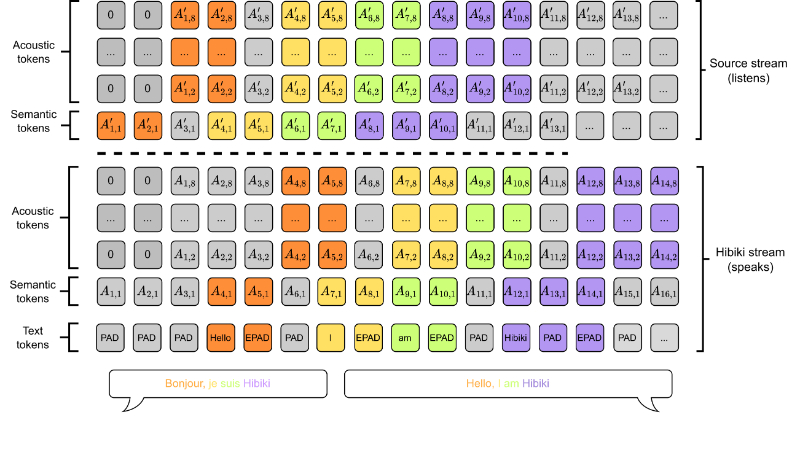
Hibiki是由Kyutai团队开发的一款实时语音翻译模型。它采用解码器架构,通过多流语言模型同步处理源语言和目标语言的语音,能够同时生成文本和音频标记,实现语音到文本(S2TT)和语音到语音(S2ST)的翻译功能。Hibiki通过弱监督学习方法,利用现成文本翻译系统的困惑度来识别最优延迟,生成对齐的合成数据,从而在实时翻译中积累足够的上下文以产生准确的翻译。在法语到英语的同时语音翻译任务中,Hibiki不仅在翻译质量、说话者保真度和自然度方面达到了行业领先水平,其简单高效的推理过程还支持批量翻译和实时设备部署,为语音翻译技术的发展树立了新的标杆。
Hibiki主要功能
-
同时语音到语音翻译(S2ST):Hibiki能够实时地将源语言的语音翻译成目标语言的语音,保持说话者的声音特征和语调。
-
同时语音到文本翻译(S2TT):除了语音翻译,Hibiki还可以生成目标语言的文本翻译,提供双重输出。
-
实时翻译:Hibiki能够在源语言语音输入的同时,逐步生成目标语言的翻译,适用于需要即时翻译的场景。
-
高保真度和自然度:通过先进的音频处理技术,Hibiki生成的翻译语音在保真度和自然度上接近人类口译。
-
批量处理:Hibiki的简单推理过程支持批量翻译,能够在单个GPU上同时处理数百个序列。
-
设备部署:Hibiki的蒸馏版本Hibiki-M能够在智能手机等设备上实时运行,适合移动应用场景。
Hibiki技术原理
-
多流语言模型:Hibiki采用多流架构,通过嵌套的全局和局部Transformer模型,同时处理源语言和目标语言的音频流,生成文本和音频标记。
-
弱监督学习:利用现成的文本翻译系统的困惑度,Hibiki通过弱监督方法识别最优延迟,生成对齐的合成数据,确保实时翻译的准确性。
-
神经音频编解码器:使用预训练的因果和流式Mimi编解码器,将音频编码为低帧率的离散标记序列,保持音频质量和语音特征。
-
联合离散音频标记建模:通过RQ-Transformer对音频流的离散标记进行时间和量化器轴的建模,确保生成的音频和文本标记高度一致。
-
上下文对齐:通过计算预训练文本翻译模型的条件对数似然,Hibiki实现了单词级别的对齐,确保翻译的流畅性和准确性。
-
温度采样和因果音频编解码:在推理时,Hibiki结合温度采样和因果音频编解码器,实现流式输入和输出,支持实时翻译。
Hibiki应用场景
-
国际会议:实时将演讲者的语音翻译成不同语言,方便跨国参会者理解。
-
远程教学:在线课堂中,不同语言背景的学生可实时听到翻译后的语音,提升学习体验。
-
视频会议:跨国企业视频会议时,实时翻译打破语言障碍,提高沟通效率。
-
旅游出行:游客在异国他乡,通过设备实时翻译与当地人交流,解决语言不通问题。
-
新闻报道:采访多语言人士时,实时翻译便于记者和观众理解,拓宽报道范围。
-
客服支持:跨国客服中心,客服人员可实时与不同语言客户沟通,提升服务质量。
Hibiki项目入口
- GitHub代码库:https://github.com/kyutai-labs/hibiki
- HuggingFace:https://huggingface.co/collections/kyutai/hibiki
- arXiv技术论文:https://arxiv.org/pdf/2502.03382
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号