FireRedASR:小红书开源的普通话自动语音识别模型
FireRedASR简介
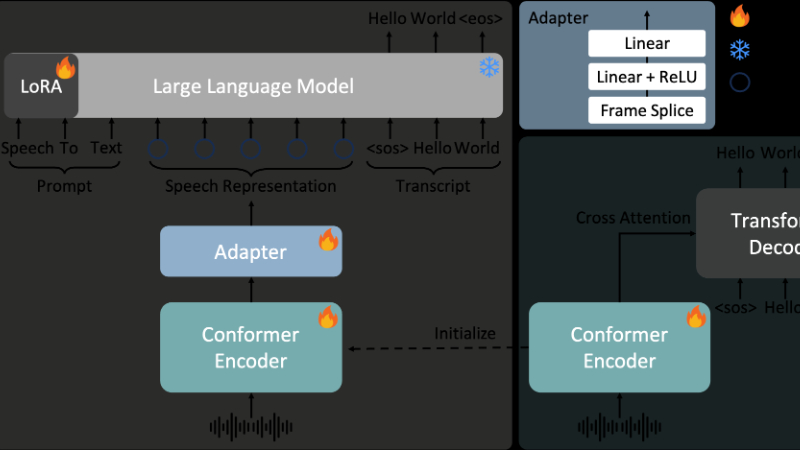
FireRedASR是由小红书开源的普通话自动语音识别(ASR)模型系列,旨在满足不同应用场景对性能和效率的需求。该模型家族包含两个变体:FireRedASR-LLM和FireRedASR-AED。FireRedASR-LLM采用编码器-适配器-LLM架构,结合了强大的语音处理能力和语言模型的语义理解能力,能够实现高精度的语音识别。FireRedASR-AED则基于注意力机制的编码器-解码器架构,注重在保持高性能的同时优化计算效率,适用于资源受限的环境。两者在公共普通话基准测试中均取得了优异的成绩,分别实现了3.05%和3.18%的平均字符错误率(CER),显著优于现有的开源和商业模型。此外,它们在多源普通话语音、歌词识别以及中文方言和英语语音识别任务中也表现出色,展现了强大的泛化能力。
FireRedASR主要功能
-
高精度普通话语音识别:FireRedASR能够在多种应用场景下实现高精度的普通话语音识别,包括短视频、直播、自动字幕、语音输入和智能助手等。
-
多源语音识别:支持多种音频来源的语音识别,能够处理不同环境中的语音数据,如视频、直播和智能助手等。
-
歌词识别:具备出色的歌词识别能力,能够在复杂的音乐环境中准确识别歌词内容。
-
中文方言和英语识别:除了普通话,FireRedASR还在中文方言和英语语音识别上表现出色,展示了广泛的适用性。
-
开源模型和代码:FireRedASR提供开源的模型权重和推理代码,支持社区驱动的改进和学术研究。
FireRedASR技术原理
-
FireRedASR-LLM架构
-
编码器-适配器-LLM架构:结合了Conformer音频编码器、轻量级音频-文本对齐适配器和预训练文本LLM,形成编码器-适配器-LLM架构。
-
Conformer编码器:用于提取语音特征,能够有效建模语音信号中的局部和全局依赖关系。
-
适配器网络:将编码器输出转换为LLM的语义空间,使LLM能够准确识别输入语音的文本内容。
-
预训练LLM:使用Qwen2-7B-Instruct的预训练权重进行初始化,增强语义理解能力。
-
-
FireRedASR-AED架构
-
注意力机制的编码器-解码器架构:结合了基于Conformer的编码器和基于Transformer的解码器,能够有效处理语音特征中的局部和全局依赖关系。
-
输入特征处理:使用80维对数Mel滤波器组(Fbank)作为输入特征,通过下采样模块和Conformer块进行处理。
-
Transformer解码器:采用标准的Transformer架构,使用固定正弦位置编码和权重绑定技术,增强模型的训练稳定性和梯度流动。
-
-
训练数据和策略
-
高质量训练数据:使用约7万小时的音频数据,其中大部分是专业标注的普通话语音,还包括约1.1万小时的英语语音数据。
-
优化的训练策略:采用渐进正则化训练策略,初期不使用正则化技术(如dropout和SpecAugment),快速收敛后逐步引入更强的正则化,以防止过拟合。
-
-
评估和性能
-
公共普通话ASR基准测试:在AISHELL-1、AISHELL-2、WenetSpeech等测试集上,FireRedASR-LLM和FireRedASR-AED分别实现了3.05%和3.18%的平均字符错误率(CER)。
-
多源语音和歌词识别:在多源普通话语音和歌词识别任务中,FireRedASR-LLM和FireRedASR-AED均表现出色,显著优于现有的开源和商业模型。
-
中文方言和英语识别:在KeSpeech和LibriSpeech测试集上,FireRedASR-LLM和FireRedASR-AED也展示了强大的泛化能力。
-
FireRedASR应用场景
-
智能语音助手:为智能设备提供高精度语音识别服务,支持语音指令交互,提升用户体验。
-
视频字幕生成:自动为视频内容生成字幕,适用于短视频、在线教育、新闻报道等领域。
-
直播互动:在直播场景中实时识别主播和观众的语音,支持弹幕互动、实时翻译等功能。
-
歌词识别:精准识别音乐中的歌词内容,适用于音乐播放器、KTV等场景。
-
语音输入法:在手机、电脑等设备上实现高效语音输入,支持多种语言和方言。
-
智能客服:用于企业客服系统,自动识别客户语音并提供快速响应,提升服务效率。
FireRedASR项目入口
- Github代码库:https://github.com/FireRedTeam/FireRedASR
- HuggingFace:https://huggingface.co/FireRedTeam/FireRedASR-AED-L
- arXiv技术论文:https://arxiv.org/pdf/2501.14350
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号