Sonic:腾讯联合浙大推出的新型音频驱动肖像动画技术
Sonic简介
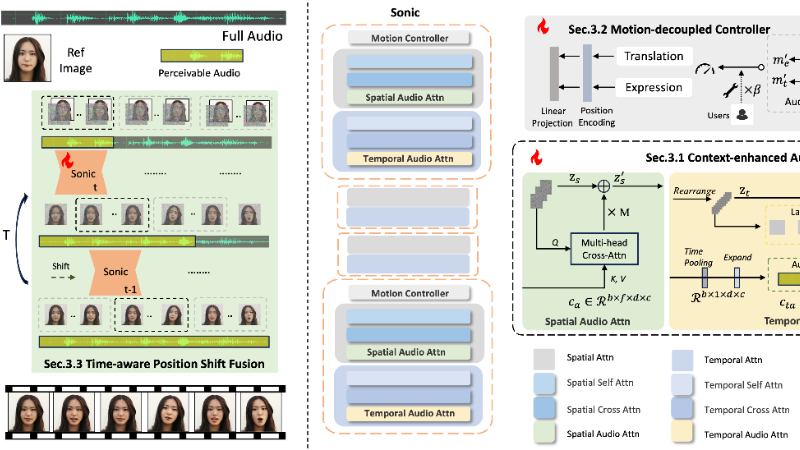
Sonic是由腾讯和浙江大学联合开发的一种新型音频驱动肖像动画技术。它通过创新的全局音频感知方法,专注于利用音频信号来生成高质量、自然且连贯的肖像动画视频。Sonic框架包含上下文增强音频学习、运动解耦控制器和时间感知位置偏移融合三大模块,能够有效提升视频质量、时间一致性、唇部同步精度和动作多样性。该技术在多项评估指标上超越了现有的最先进方法,展现了强大的性能和应用潜力,尤其在长视频生成和复杂场景下表现出色,为虚拟现实、影视制作等领域带来了新的技术突破。
Sonic主要功能
-
高质量肖像动画生成:Sonic能够从单一参考图像和输入音频生成高质量的肖像动画视频,确保视频的视觉效果逼真且自然。
-
唇部同步:Sonic在生成视频时能够精确同步唇部动作与输入音频,确保说话人物的口型与音频完全匹配。
-
丰富的面部表情和头部运动:Sonic不仅能够生成同步的唇部动作,还能生成丰富的面部表情和自然的头部运动,使动画更加生动。
-
长视频生成:Sonic能够处理长时间的视频生成任务,确保生成的视频在整个过程中保持稳定和连贯。
-
多样化的动作生成:Sonic支持生成多样化的面部和头部动作,增强动画的表现力和趣味性。
Sonic技术原理
-
上下文增强音频学习(Context-enhanced Audio Learning):
-
音频特征提取:使用预训练的Whisper-Tiny模型提取音频特征,捕捉音频中的长程时间信息。
-
多尺度理解:将音频特征进行多尺度理解,并通过线性层投影到匹配的维度,以指导空间和时间帧的生成。
-
空间交叉注意力:将音频信号注入到空间交叉注意力层中,指导生成的空间特征,使其与音频同步。
-
-
运动解耦控制器(Motion-decoupled Controller):
-
运动解耦:将头部运动和表情运动解耦,通过两个显式参数(头部运动桶和表情运动桶)独立控制。
-
参数学习:在训练阶段,通过视频片段的边界框和相对地标的方差计算运动桶参数,并通过位置编码和线性投影加入到ResNet块中。
-
用户定义:支持用户定义夸张的动作,并通过音频和参考图像自适应预测运动桶参数。
-
-
时间感知位置偏移融合(Time-aware Position Shift Fusion):
-
时间感知偏移窗口:通过时间感知偏移窗口将片段内的音频感知扩展到全局片段间音频感知,增强模型的时间建模能力。
-
滑动窗口处理:在每个时间步长上,模型从不同的位置开始滑动窗口,逐步融合片段间的潜在特征,确保长视频的连续性和稳定性。
-
循环填充:在长序列的末尾,采用循环填充策略,确保音频提示和潜在特征的相对位置不变。
-
Sonic应用场景
-
虚拟现实(VR)与增强现实(AR):为虚拟角色生成逼真的面部动画,增强沉浸感。
-
影视制作:快速生成角色的说话动画,降低制作成本,提高效率。
-
在线教育:创建生动的虚拟教师形象,提升学习体验。
-
游戏开发:生成游戏中的NPC(非玩家角色)动画,使角色更加逼真。
-
社交媒体与短视频:为用户生成个性化的动画视频,丰富内容创作。
-
医疗康复:辅助语言康复训练,通过生动的动画激励患者练习发音。
Sonic项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号