WorldSense:小红书联合交大推出的多模态评估新基准
WorldSense简介
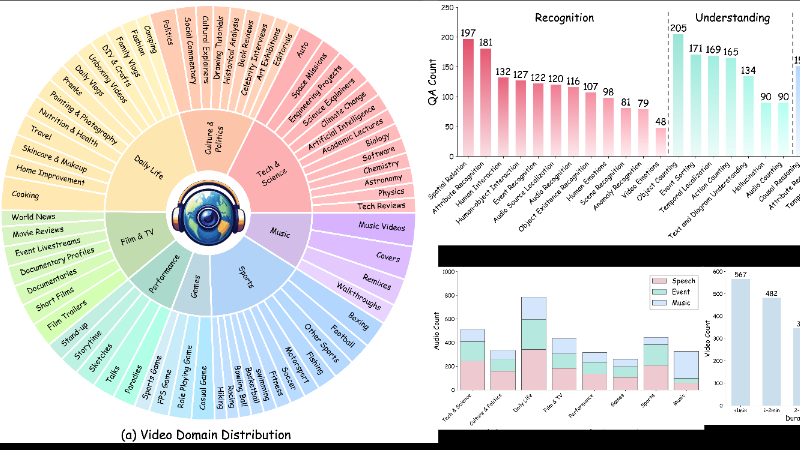
WorldSense是由小红书和上海交通大学联合开发的首个用于评估多模态大语言模型(MLLMs)在真实世界场景中对视听文本输入综合理解能力的基准测试。该基准测试通过强调音频和视频信息的紧密耦合,以及涵盖多样化的真实世界视频和任务,旨在全面评估模型的多模态理解能力。开发团队精心设计了1662个音频-视频同步视频,覆盖8个主要领域和67个细分类别,并提供了3172个高质量标注的多选问答对,以确保评估的准确性和可靠性。WorldSense的推出为推动MLLMs在多模态理解方面的发展提供了重要平台,使其更接近人类的感知能力。
WorldSense主要功能
-
多模态理解评估:WorldSense评估多模态大语言模型(MLLMs)在真实世界场景中对视听文本输入的综合理解能力。
-
多样化任务覆盖:包含1662个音频-视频同步视频,涵盖8个主要领域和67个细分类别,以及3172个多选问答对,覆盖26种不同的认知任务。
-
高质量标注:所有问答对均由80名专家标注,并经过多轮人工和自动验证,确保标注的准确性和可靠性。
-
性能基准测试:通过对现有多种MLLMs的广泛评估,揭示这些模型在真实世界多模态理解方面的能力和局限性。
WorldSense技术原理
-
多模态协作:WorldSense强调音频和视频信息的紧密耦合,每个问题都需要同时处理这两种模态才能得出正确答案。这种设计严格测试模型同时处理多种感官输入的能力。
-
数据收集与过滤:从大型数据集(如FineVideo和MusicAVQA)中系统性地筛选高质量视频,确保视频具有丰富的视听语义和时间动态。
-
标注与质量控制:由专业标注团队创建高质量的多选问答对,并通过人工和自动化验证系统(如Qwen2-VL和Video-LLaMA2)进行多轮质量控制,确保问题的清晰性和多模态需求。
-
多层次评估:设计了从基本感知到复杂推理的多层次评估任务,涵盖识别、理解和推理三个层次,系统评估模型的多模态理解能力。
-
消融研究:通过不同模态配置的消融研究,分析视觉信息、音频信息和视频帧采样密度对模型性能的影响,揭示多模态协作在真实世界理解中的重要性。
WorldSense应用场景
-
自动驾驶:通过整合视觉和听觉信息,帮助自动驾驶系统更准确地感知周围环境,例如识别交通标志、行人、车辆喇叭声等。
-
智能教育:为教育工具提供更丰富的交互体验,例如通过视频和音频结合的方式解释复杂的科学概念或历史事件。
-
智能客服:在客服场景中,通过分析用户上传的视频和音频内容,快速准确地理解问题并提供解决方案。
-
安防监控:在监控系统中,结合视觉和听觉信号,更精准地识别异常行为或事件,例如检测可疑人员或异常声音。
-
智能助手:提升智能助手在家庭或办公场景中的交互能力,使其能够更好地理解用户的指令和需求。
-
内容创作:在视频编辑和内容创作中,帮助创作者分析视频和音频素材,提供更智能的剪辑建议或自动生成字幕等。
WorldSense项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号