Zonos-v0.1:Zyphra推出的文本转语音模型
Zonos-v0.1简介
Zonos-v0.1是由Zyphra团队开发的文本到语音(TTS)模型,于2025年2月10日发布。它包含两个1.6B参数的模型:一个Transformer模型和一个SSM混合模型,后者是首个开源的SSM模型,专为TTS设计。Zonos-v0.1能够生成富有表现力的自然语音,并支持高保真语音克隆,仅需5到30秒的语音片段即可实现。它还支持多种语言(主要为英语),并可调节语速、音高、音质和情感,输出原生44KHz的语音。Zonos-v0.1经过约20万小时的语音数据训练,采用两阶段训练方法,优化了模型的鲁棒性和质量。其高效的推理引擎和优化架构使其在延迟和内存使用上表现出色。此外,Zonos-v0.1通过API和模型游乐场提供服务,支持每月免费100分钟的使用,并有多种订阅套餐可供选择。
Zonos-v0.1主要功能
-
高保真语音克隆:Zonos-v0.1能够通过5到30秒的语音片段实现高质量的语音克隆,生成的语音与原始语音高度相似。
-
多语言支持:主要支持英语,同时对中文、日语、法语、西班牙语和德语也有较好的支持,但对其他语言的支持不够稳健。
-
情感和语调控制:可以根据说话速率、音高标准差、音质和情感(如悲伤、恐惧、愤怒、快乐和惊讶)进行调节,生成富有表现力的自然语音。
-
高质量语音输出:原生支持44KHz的语音输出,确保生成的语音清晰自然。
-
API和模型游乐场:提供Python和TypeScript的API接口,用户可以通过Zonos的模型游乐场和API访问模型,进行语音生成和克隆。
-
灵活的订阅和定价方案:提供每分钟0.02美元的固定费率,以及每月免费100分钟和Pro Tier每月5美元提供300分钟的订阅选项,支持无限语音克隆和无并发生成限制。
Zonos-v0.1技术原理
-
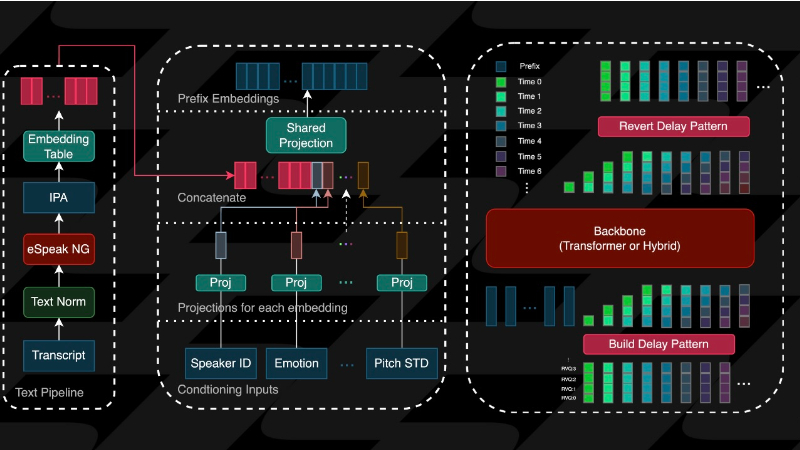
双模型架构:Zonos-v0.1包含一个1.6B参数的Transformer模型和一个1.6B参数的SSM混合模型。SSM混合模型是首个开源的SSM模型,用于TTS。
-
训练数据:模型基于约20万小时的语音数据训练,涵盖中性语调(如有声读物旁白)和富有表现力的语音,主要为英语数据。
-
两阶段训练方法:
-
第一阶段:使用文本前缀和说话者嵌入进行预训练,占训练时间的70%。
-
第二阶段:加入条件输入(如语速、音高、音质和情感)并略微增加高质量数据的权重,占训练时间的30%。
-
-
高比特率音频编码器:使用descript音频编解码器(DAC)对原始语音波形进行编码,生成高质量的音频令牌。DAC是一个高比特率的自动编码器,虽然增加了预测难度,但提高了生成质量。
-
音素转换:将输入文本标准化后,使用eSpeak音素转换器将文本转换为音素,再由Transformer或混合模型预测音频令牌。
-
说话者嵌入:模型接收说话者嵌入作为输入,实现语音克隆能力。
-
条件输入:模型接收多个条件输入(如语速、音高、音质和情感),实现对生成语音的灵活控制。
-
优化的推理引擎:高效的推理引擎支持快速的首次音频生成(TTFA),混合模型在延迟和内存使用上表现更优,得益于其基于Mamba2的架构,减少了对注意力模块的依赖。
Zonos-v0.1应用场景
-
有声读物与音频内容创作:将文字书籍、文章或博客转换为高质量的有声内容,为听众提供更丰富的听觉体验。
-
虚拟助手与客服:为智能设备、在线客服系统等提供自然流畅的语音交互,提升用户体验。
-
视频内容制作:为视频添加旁白、配音或角色对话,支持多语言配音,满足不同地区观众的需求。
-
教育与学习工具:为在线课程、教育软件生成生动的语音讲解,帮助学生更好地理解和吸收知识。
-
游戏与娱乐:为游戏角色、互动故事或虚拟现实应用提供个性化的语音输出,增强沉浸感。
-
语音播报与通知:用于新闻播报、交通信息提示、企业内部通知等场景,实现高效的信息传递。
Zonos-v0.1项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号