VideoCaptioner:能够实现视频字幕的全流程处理
VideoCaptioner 简介
VideoCaptioner 是一款智能字幕处理工具,基于大语言模型(LLM)技术,能够实现视频字幕的全流程处理,包括语音识别、字幕断句、优化、翻译以及字幕视频合成等功能。它支持多种语音识别引擎,如在线接口和本地离线的 Whisper 模型,无需高性能 GPU 即可高效运行。软件还提供丰富的字幕样式模板和多种格式支持(如 SRT、ASS、VTT 等),并具备人声分离、字级时间戳等实用功能。其直观的操作界面和低消耗的模型设计,让字幕制作变得简单高效,适合视频创作者、教育工作者以及翻译人员等各类用户,帮助他们快速生成高质量字幕,提升工作效率。
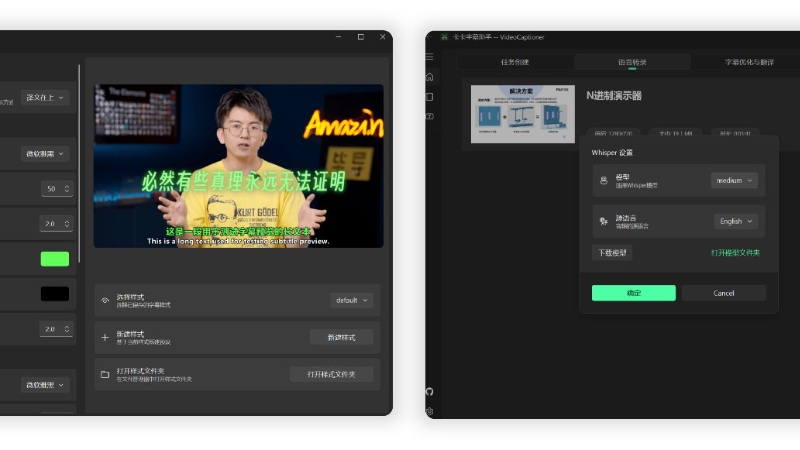
VideoCaptioner 主要功能
-
多平台视频下载与处理
-
支持国内外主流视频平台(如B站、YouTube)的视频下载和字幕处理。
-
自动提取视频原有字幕进行处理。
-
-
专业的语音识别引擎
-
提供多种在线语音识别接口,效果媲美剪映(免费、高速)。
-
支持本地Whisper模型(保护隐私、可离线),包括WhisperCpp和fasterWhisper两种版本。
-
-
字幕智能纠错
-
自动优化专业术语、代码片段和数学公式格式。
-
上下文进行断句优化,提升阅读体验。
-
支持文稿提示,使用原有文稿或者相关提示优化字幕断句。
-
-
高质量字幕翻译
-
结合上下文的智能翻译,确保译文兼顾全文。
-
通过Prompt指导大模型反思翻译,提升翻译质量。
-
使用序列模糊匹配算法,保证时间轴完全一致。
-
-
字幕样式调整
-
提供丰富的字幕样式模板(如科普风、新闻风、番剧风等)。
-
支持多种格式字幕视频(如SRT、ASS、VTT、TXT)。
-
-
批量处理:支持批量视频字幕合成,提升处理效率。
-
直观的字幕编辑查看界面:提供实时预览和快捷编辑功能。
VideoCaptioner 技术原理
-
大语言模型(LLM)
-
利用LLM在理解上下文方面的优势,对语音识别生成的字幕进行智能断句、校正和翻译。
-
内置基础大语言模型(如
gpt-4o-mini),无需配置即可使用,支持标准OpenAI API格式,兼容多种LLM服务。
-
-
语音识别
-
支持在线和本地离线两种语音识别方式。
-
本地Whisper模型包括WhisperCpp和fasterWhisper两种版本,后者效果更好,支持CUDA加速。
-
-
字幕优化与翻译
-
通过Prompt指导大模型进行反思和优化翻译,确保翻译质量。
-
使用序列模糊匹配算法,保证字幕时间轴与视频完全一致。
-
-
人声分离和字级时间戳
-
支持VAD(语音活动检测)和人声分离,减少背景噪音干扰。
-
提供字级时间戳功能,确保字幕与视频画面完美同步。
-
-
多线程处理:支持多线程优化和翻译,提升处理效率。
-
文稿匹配:支持术语表、原字幕文稿和修正要求等多种文稿匹配方式,辅助校正字幕和翻译。
VideoCaptioner 应用场景
-
视频创作者:为自媒体视频、Vlog 添加精准字幕,提升内容可读性和观众体验。
-
教育领域:为教学视频生成字幕,方便学生学习,尤其是外语教学视频的翻译字幕。
-
影视制作:为电影、电视剧、纪录片等添加字幕,支持多种字幕样式和格式,满足不同需求。
-
会议记录:将会议录音转录为字幕,便于整理和回顾会议内容,提高工作效率。
-
社交媒体:为短视频平台(如抖音、B站)的内容添加字幕,增强互动性和传播效果。
-
多语言支持:为外语视频生成翻译字幕,帮助观众更好地理解内容,拓展内容的受众群体。
VideoCaptioner 项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号