MoMask:新型的文本驱动3D人类动作生成框架
MoMask简介
MoMask是一种新型的文本驱动3D人类动作生成框架,通过层次化的量化方案和双向变换器实现高质量的动作合成。它采用残差量化技术将动作分解为多层离散标记,有效减少量化误差,提升生成精度。MoMask包含两个核心组件:掩码变换器(M-Transformer)和残差变换器(R-Transformer)。M-Transformer基于BERT架构,通过随机掩码和预测动作标记,实现高效的文本到动作的映射;R-Transformer则负责逐层预测残差标记,进一步优化动作细节。在HumanML3D和KIT-ML数据集上,MoMask的FID指标分别达到0.045和0.228,显著优于现有方法,同时支持文本引导的时间插值等扩展应用。
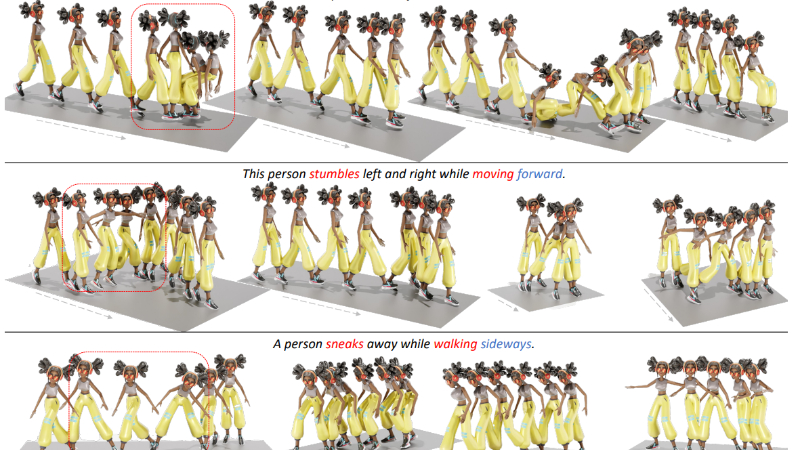
MoMask主要功能
-
高质量3D动作生成:根据文本描述生成高保真度的3D人类动作,能够精确捕捉动作的细节和语义信息。
-
高效生成:通过双向变换器和层次化量化技术,MoMask能够在较少的迭代步骤内生成完整的动作序列,显著提高生成效率。
-
多模态动作生成:支持从同一文本描述生成多样化的动作,满足不同应用场景的需求。
-
文本引导的时间插值:可以用于修复或填充动作序列中的特定时间段,实现流畅的动作过渡。
-
扩展性:无缝应用于相关任务(如动作编辑、动作修复等),无需额外的模型微调。
MoMask技术原理
-
层次化量化方案(Residual Vector Quantization, RVQ):
-
将动作序列通过多层量化分解为离散的动作标记,每一层捕捉不同层次的细节。
-
通过残差量化逐步减少量化误差,提高动作表示的精度。
-
量化丢弃(Quantization Dropout)策略随机禁用部分量化层,增强模型的鲁棒性。
-
-
掩码变换器(Masked Transformer, M-Transformer):
-
基于BERT架构,随机掩码基础层的动作标记,并根据文本输入预测这些掩码标记。
-
掩码比例通过余弦函数动态调整,增强模型对不同上下文的适应能力。
-
支持并行预测掩码标记,快速生成基础层的动作序列。
-
-
残差变换器(Residual Transformer, R-Transformer):
-
逐层预测后续量化层的动作标记,基于当前层的标记序列和文本输入。
-
通过多层预测逐步细化动作细节,提升生成动作的质量。
-
-
双向变换器架构:
-
利用双向上下文信息,避免单向解码的累积误差,提升生成动作的连贯性和准确性。
-
-
分类器自由引导(Classifier-Free Guidance, CFG):
-
在生成阶段,通过调整条件和无条件生成的权重,优化生成结果的语义对齐和多样性。
-
-
多任务学习能力:
-
通过共享模型架构和训练机制,MoMask能够适应多种与动作生成相关的任务,如时间插值和动作编辑。
-
MoMask应用场景
-
视频游戏:根据剧情文本动态生成角色动作,提升游戏的沉浸感和交互性。
-
虚拟现实(VR)和增强现实(AR):实时生成与用户交互或场景描述匹配的虚拟角色动作,增强虚拟环境的真实感。
-
动画制作:快速生成动画角色的动作序列,辅助动画师进行创作,提高制作效率。
-
动作捕捉数据增强:对有限的动作捕捉数据进行扩展,生成更多样的动作样本,丰富动作库。
-
虚拟健身和运动指导:根据语音或文本指令生成标准的健身动作,辅助用户进行锻炼。
-
智能教育:在虚拟教学场景中生成教师或角色的动作,增强教学的趣味性和互动性。
MoMask项目入口
- 项目主页:https://ericguo5513.github.io/momask
- Github代码库:https://github.com/EricGuo5513/momask
- arXiv技术论文:https://arxiv.org/pdf/2312.00063
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号