PDF to Podcast:将PDF文档高效转换为音频内容
PDF to Podcast简介
“PDF to Podcast”是由NVIDIA AI Blueprint团队开发的一项创新应用,旨在将PDF文档高效转换为音频内容,生成引人入胜的播客。它基于NVIDIA强大的AI技术,通过自然语言处理和文本转语音技术,将PDF中的文字信息转化为流畅的音频,支持单人或多人播客模式。用户可以指定上下文PDF文件和引导提示,进一步优化生成内容的准确性和相关性。该应用支持灵活部署,可运行在非GPU加速的机器上,也可本地托管NVIDIA NIM以提升性能。它适用于学术研究、商业分析、教育培训、新闻媒体、个人知识管理以及行业报告等多种场景,为用户提供了便捷、高效的信息获取方式。
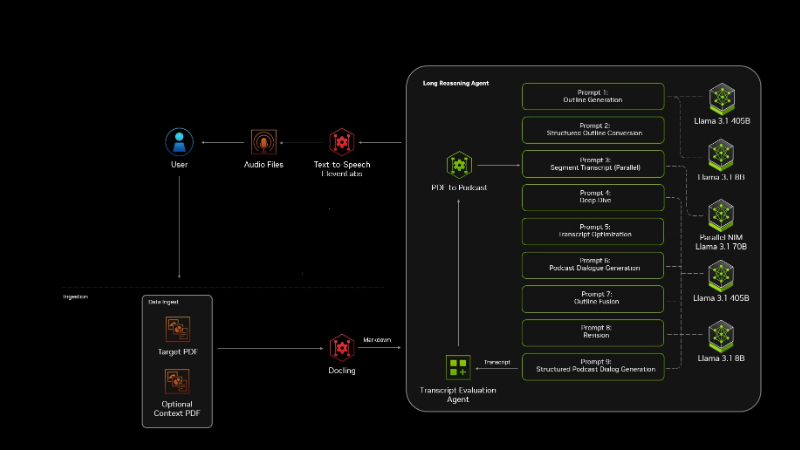
PDF to Podcast主要功能
-
PDF转换为音频:将目标PDF文档转换为音频内容,生成单人或多人播客。
-
多PDF支持:支持多个上下文PDF文件,作为额外参考信息,提升生成内容的准确性和丰富性。
-
引导提示:用户可以指定引导提示,聚焦生成脚本的重点内容。
-
灵活部署:支持在非GPU加速的机器或虚拟机上运行,也可以本地部署NVIDIA NIM。
-
API集成:通过NVIDIA API和ElevenLabs API进行推理和文本转语音服务。
-
自定义模型和配置:允许用户根据硬件配置和需求自定义模型选择和GPU使用。
-
追踪和监控:提供Jaeger实例进行系统调试和监控。
PDF to Podcast技术原理
-
文档摄取和提取:使用Docling服务进行PDF内容提取,将PDF文档转换为可处理的文本数据。
-
自然语言处理:
-
利用NVIDIA NIM微服务进行响应生成,支持不同大小的Llama模型(如Llama 3.1-8B, 70B, 405B)。
-
通过上下文PDF文件提供额外参考信息,提升生成内容的准确性。
-
-
文本转语音(TTS):使用ElevenLabs的文本转语音服务,将生成的文本内容转换为自然流畅的音频。
-
微服务架构:采用Docker Compose脚本启动和管理各个微服务,包括文档提取、响应生成和文本转语音服务。
-
环境变量和API密钥:通过设置环境变量和API密钥,确保各个服务之间的安全通信和配置管理。
-
硬件加速:支持GPU加速,推荐在大规模部署和快速预处理PDF时使用GPU,以提升性能。
-
安全性:在生产环境中建议使用SSL/TLS加密,配置适当的安全头,遵循Web安全最佳实践。
PDF to Podcast应用场景
-
学术研究:研究人员将学术论文或研究报告转换为音频,方便在通勤或运动时收听,节省时间并提高信息获取效率。
-
商业分析:企业分析师将市场报告、财务报表等文件转化为播客,便于在外出或休息时快速了解关键数据和趋势。
-
教育培训:教师将教学资料或课件转换为音频,供学生在课后或路上收听,增强学习的灵活性。
-
新闻媒体:记者将新闻稿或深度报道转换为音频内容,方便听众在开车或做家务时获取新闻资讯。
-
个人知识管理:个人将电子书、笔记等资料转换为音频,利用碎片时间进行学习和知识积累。
-
行业报告:行业分析师将行业动态报告、趋势分析等转换为音频,帮助从业者在忙碌中及时掌握行业动态。
PDF to Podcast项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号