UltraMem:字节豆包大模型团队推出的超稀疏记忆网络架构
UltraMem简介
UltraMem是由字节跳动豆包大模型团队开发的一种新型超稀疏记忆网络架构。它通过引入大规模超稀疏记忆层,显著降低了Transformer模型在推理过程中的延迟,同时保持了模型性能。UltraMem在设计上对Product Key Memory(PKM)进行了多项改进,包括采用Tucker分解提升检索精度、引入虚拟内存扩展技术减少内存访问成本,并通过多核评分机制优化性能。在实验中,UltraMem展现出比Mixture of Experts(MoE)更强的扩展能力和更高的推理速度,其最大模型拥有2000万个记忆槽位,能够在给定计算预算内实现最先进的推理速度和模型性能,为未来大规模语言模型的开发提供了新的高效解决方案。
UltraMem主要功能
-
降低推理延迟:通过引入超稀疏记忆层,UltraMem显著减少了模型在推理过程中的延迟,使其在实时应用中更加高效。
-
保持模型性能:在减少推理延迟的同时,UltraMem能够保持甚至提升模型的性能,确保其在各种基准测试中的表现优异。
-
扩展性强:UltraMem展示了优越的扩展能力,能够在不显著增加计算复杂度的情况下,通过增加参数数量来提升模型性能。
-
适用于资源受限环境:UltraMem的设计使其能够在计算资源有限的环境中高效运行,适用于实时应用和大规模模型部署。
UltraMem技术原理
-
超稀疏记忆层:UltraMem基于Product Key Memory(PKM)的概念,通过引入大规模超稀疏记忆层来扩展模型参数,同时保持计算复杂度不变。
-
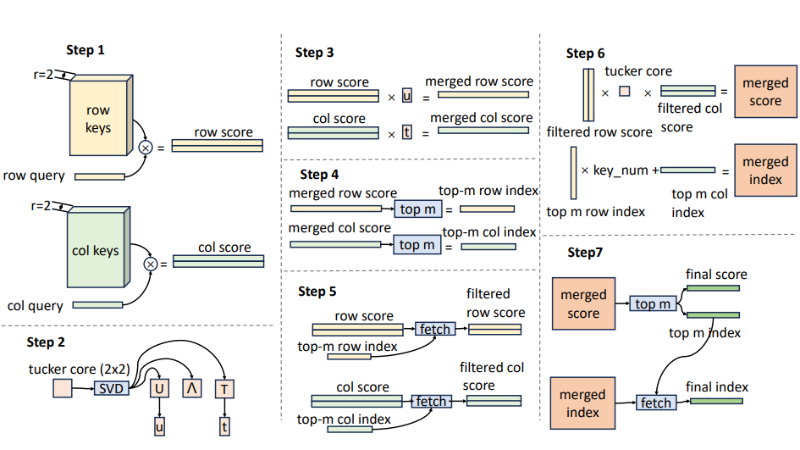
Tucker Decomposed Query-Key Retrieval(TDQKR):采用Tucker分解代替传统的乘积量化,以提高检索精度和效率。TDQKR通过分解查询和键的矩阵,减少了计算复杂度。
-
Implicit Value Expansion(IVE):通过虚拟内存扩展物理内存表,减少内存访问并扩大内存规模。IVE利用多个线性投影器对原始内存值进行重新参数化,从而实现内存表的虚拟扩展。
-
Multi-Core Scoring(MCS):为单个值分配多个分数,以提高模型性能。MCS通过将Tucker核心分解为多个组件核,生成多个独立的评分图,从而增强模型的表达能力。
-
改进的初始化和学习率策略:UltraMem对值的初始化和学习率进行了优化,确保模型在训练初期和中期的稳定性和收敛性。值的学习率设置为其他参数的十倍,并线性衰减至训练结束时与其他参数一致。
-
并行化训练支持:为了支持大规模模型的训练,UltraMem采用了Megatron的3D并行化技术,包括流水线并行、数据并行和张量并行,以确保模型参数和优化器状态能够高效分布在多个设备上。
UltraMem应用场景
-
实时对话系统:UltraMem的低延迟特性使其能够快速生成回复,适用于智能客服、聊天机器人等需要实时交互的场景。
-
内容推荐:在内容推荐系统中,UltraMem可以快速处理用户数据并生成个性化推荐,提升用户体验。
-
智能写作辅助:为写作工具提供实时的文本生成和校对功能,帮助用户快速撰写文章、邮件等。
-
语音助手:在语音助手应用中,UltraMem能够快速响应语音指令,提供流畅的交互体验。
-
搜索引擎优化:通过快速生成高质量的文本内容,UltraMem可以用于搜索引擎的自然语言处理,提升搜索结果的相关性和准确性。
-
教育辅导:在教育领域,UltraMem可以用于智能辅导系统,实时解答学生的问题,提供个性化的学习建议。
UltraMem项目入口
- arXiv技术论文:https://arxiv.org/pdf/2411.12364
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号