Generator:专注于真核生物DNA序列的生成与理解
Generator简介
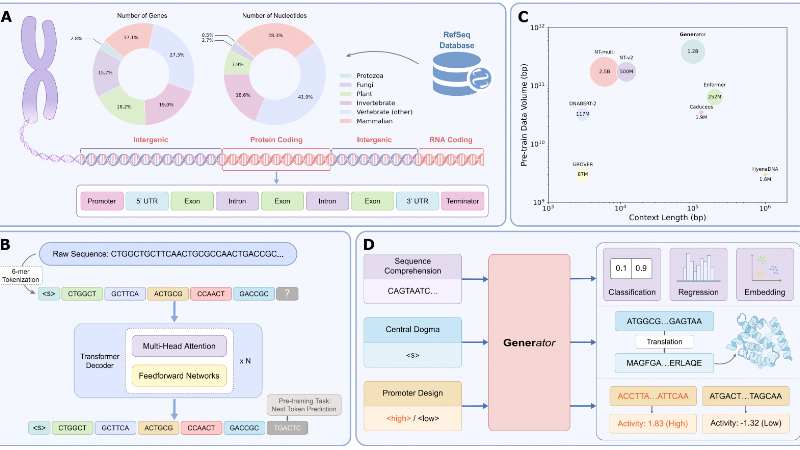
Generator是由阿里巴巴云Apsara Lab联合中国科学技术大学、香港科技大学(广州)和香港科技大学的研究团队共同开发的一款长文本生成型基因组基础模型。该模型基于Transformer解码器架构,拥有98k碱基对的上下文长度和12亿参数,专注于真核生物DNA序列的生成与理解。它在大规模数据集上进行训练,展现出卓越的基因组序列生成和优化能力,能够生成与已知蛋白家族结构相似的DNA序列,并在启动子设计等任务中达到行业领先水平。Generator的开发为基因组研究和生物技术应用提供了强大的工具,有望推动精准医学和合成生物学的发展。
Generator主要功能
-
基因组序列生成:
-
能够生成与已知蛋白家族结构相似的DNA序列,支持从基因编码序列到功能性蛋白质的生成,符合分子生物学的中心法则。
-
可以设计具有特定活性特征的启动子序列,为基因表达调控提供精确的序列优化方案。
-
-
基因组序列理解与分类:
-
在多种基因组分类任务中表现出色,能够准确识别基因类型和生物分类群,支持从短到长的基因组序列分类。
-
提供对基因组上下文的深度理解,适用于多物种基因组分析。
-
-
生物技术应用支持:
-
为合成生物学提供序列设计工具,支持定制化的基因组编辑和生物分子设计。
-
通过生成与目标蛋白家族相似的DNA序列,为药物设计和生物治疗提供潜在的分子基础。
-
-
基因组干预与预测:
-
提供对基因组功能区域的预测能力,例如启动子、增强子等调控元件的识别。
-
支持基于序列的基因表达预测,为基因调控网络的研究提供计算支持。
-
Generator技术原理
-
长上下文生成架构:
-
基于Transformer解码器架构,支持长达98k碱基对的上下文长度,能够处理复杂的基因组序列。
-
采用6-mer分词器,将DNA序列分解为长度为6的核苷酸片段,平衡了序列分辨率和上下文覆盖范围。
-
-
大规模预训练:
-
在包含3860亿碱基对的真核生物DNA数据集上进行预训练,通过下一个token预测(NTP)任务学习基因组序列的语义和结构。
-
使用随机化起始位置和Flash Attention等技术优化预训练过程,提升模型对序列对齐变化的鲁棒性。
-
-
基因序列专注训练:
-
采用基因序列训练策略,专注于基因区域的语义信息,避免非基因区域的噪声干扰。
-
通过丰富的基因区域数据提升模型在下游任务中的表现,尤其是在功能序列生成和分类任务中。
-
-
中心法则验证与优化:
-
通过生成与已知蛋白家族结构相似的DNA序列,验证模型对分子生物学中心法则的遵循。
-
使用AlphaFold3等工具对生成的蛋白质结构进行验证,确保生成序列的功能性和可折叠性。
-
-
启动子设计与优化:
-
利用监督微调(SFT)技术,结合启动子活性数据,设计具有特定活性特征的启动子序列。
-
支持通过提示(prompt)引导的序列生成,实现精确的基因表达调控设计。
-
-
多物种泛化能力:
-
在多物种基因组数据上进行预训练,支持模型对不同生物分类群的泛化能力。
-
通过跨物种的基因组序列理解,为生物进化和基因功能研究提供支持。
-
Generator应用场景
-
基因组编辑与合成生物学:设计特定功能的基因序列,优化启动子和增强子,用于精准基因编辑和合成生物系统的构建。
-
药物研发:生成与目标蛋白家族相似的DNA序列,为新药靶点发现和生物治疗提供潜在的分子模板。
-
基因表达调控:设计具有特定活性的启动子序列,调控基因表达水平,支持基因治疗和基因调控网络研究。
-
基因注释与功能预测:辅助识别基因组中的功能区域,预测基因功能,支持基因组注释和功能基因组学研究。
-
生物进化研究:通过生成跨物种的基因组序列,探索基因家族的进化路径,研究生物进化机制。
-
临床基因组学:辅助分析疾病相关基因变异,设计用于疾病诊断和治疗的基因组工具,推动精准医学发展。
Generator项目入口
- 项目主页:https://generteam.github.io/
- Github代码库:https://github.com/GenerTeam/GENERator
- HuggingFace:https://huggingface.co/GenerTeam
- arXiv技术论文:https://arxiv.org/pdf/2502.07272
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号