MoBA:Moonshot AI提出的新型注意力架构
MoBA简介
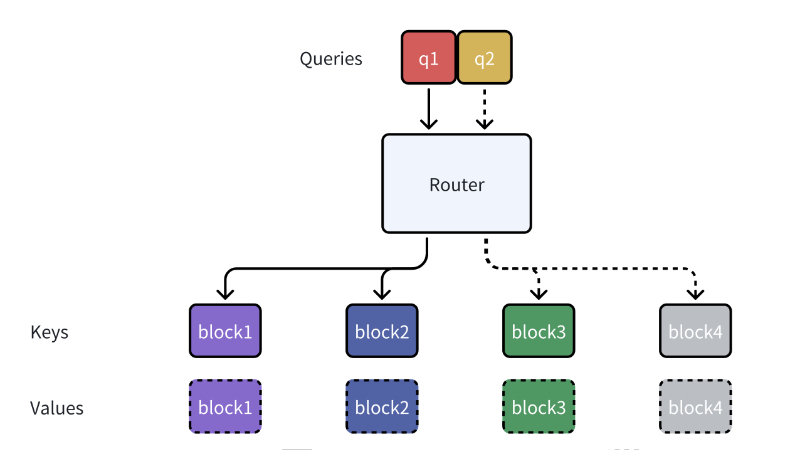
MoBA(Mixture of Block Attention)是由Moonshot AI团队开发的一种创新的注意力架构,旨在提升大型语言模型(LLMs)处理长文本序列的效率和性能。MoBA借鉴了Mixture of Experts(MoE)的思想,通过将上下文划分为多个块,并动态选择与查询最相关的块进行注意力计算,从而在保持模型性能的同时显著降低计算复杂度。该架构不仅能够无缝切换于全注意力与稀疏注意力模式,还具备出色的可扩展性,能够在处理长达数百万甚至千万级的序列时保持高效。MoBA的设计理念强调“少结构”,让模型自主决定关注点,避免预定义的偏见,为LLMs在复杂推理和长文本处理任务中提供了新的解决方案。
MoBA主要功能
-
高效处理长文本序列:MoBA通过动态稀疏注意力机制,显著降低计算复杂度,使大型语言模型能够高效处理长达数百万甚至千万级的长文本序列。
-
保持性能与效率的平衡:在提高效率的同时,MoBA能够保持与传统全注意力机制相当的性能,尤其在长文本任务中表现出色。
-
无缝集成与切换:MoBA可以作为全注意力的替代品,无缝集成到现有的语言模型中,支持在训练和推理过程中动态切换,无需额外的训练成本。
-
提升模型的长文本理解能力:通过动态关注与查询最相关的上下文块,MoBA增强了模型对长文本的推理和理解能力,尤其适用于复杂推理和长文档处理任务。
-
支持大规模模型扩展:MoBA的设计使其能够轻松扩展到大规模语言模型中,同时保持低计算开销,为模型的持续扩展提供了技术支持。
MoBA技术原理
-
块划分与稀疏注意力:MoBA将长文本序列划分为多个固定大小的块(block),并通过门控机制动态选择与每个查询最相关的块进行注意力计算,从而实现稀疏注意力,显著减少计算量。
-
动态门控机制:基于Mixture of Experts(MoE)的思想,MoBA引入动态门控网络,计算查询与每个块的相关性得分,并选择得分最高的前k个块作为注意力目标,使模型能够自主决定关注点。
-
因果性保持:为确保自回归语言模型的因果性,MoBA限制查询不能关注未来的块,并在当前块中应用因果掩码,避免信息泄露。
-
细粒度块划分:通过更细粒度的块划分,MoBA能够提高模型对长文本的处理精度,类似于MoE中细粒度专家划分的技术优势。
-
与全注意力的混合:MoBA支持与全注意力机制的混合使用,允许在训练和推理过程中动态切换,以实现效率和性能的最佳平衡。
-
优化实现:结合FlashAttention和MoE的优化技术,MoBA实现了高效的并行计算和内存优化,进一步提升了处理长序列的速度和效率。
MoBA应用场景
-
长文档处理:高效处理长篇文档,如法律文书、学术论文、技术手册等,支持快速信息检索和内容理解。
-
复杂推理任务:在需要长文本推理的场景中,如数学问题解答、逻辑推理、代码理解等,提升模型的推理能力。
-
历史数据分析:分析和总结长序列的历史数据,如金融时间序列分析、用户行为日志分析等。
-
语言模型扩展:用于扩展语言模型的上下文窗口,支持更长的输入和输出,提升模型的通用性和灵活性。
-
多模态任务:在涉及长文本描述的多模态任务中,如图文匹配、视频字幕生成等,优化文本处理效率。
-
实时交互系统:在需要快速响应的场景中,如智能客服、实时翻译、聊天机器人等,通过高效处理长文本提升交互速度和质量。
MoBA项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号