OSUM:西北工业大学开源的语音理解模型
OSUM简介
OSUM是由西北工业大学音频、语音与语言处理研究组(ASLP@NPU)开发的开源语音理解模型,旨在推动学术界在有限资源下对语音理解语言模型(SULMs)的研究。该模型结合了Whisper编码器和Qwen2语言模型,支持包括自动语音识别(ASR)、语音情感识别(SER)、说话风格识别(SSR)等在内的八种语音任务。OSUM通过创新的ASR+X训练策略,实现了高效稳定的多任务训练,并在多种任务上展现出与行业先进模型相当甚至更优的性能。开发团队强调透明性,公开了数据准备和训练方法,为学术研究提供了宝贵的参考和指导。
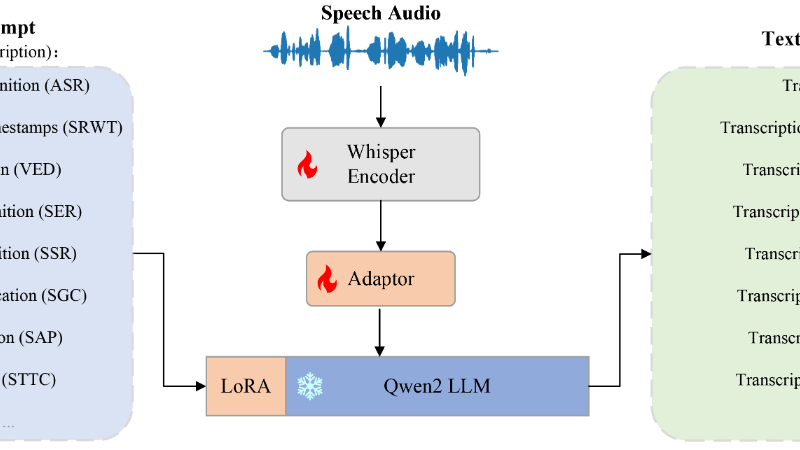
OSUM主要功能
-
自动语音识别(ASR):将语音转换为文本,支持多种语言和口音。
-
带时间戳的语音识别(SRWT):在语音转录的同时标记每个词的起始和结束时间。
-
声音事件检测(VED):识别语音中的特定声音事件,如笑声、咳嗽等。
-
语音情感识别(SER):识别语音中的情感,如快乐、愤怒、悲伤等。
-
说话风格识别(SSR):识别说话者的风格,如新闻播报、童话故事等。
-
说话者性别分类(SGC):识别说话者的性别。
-
说话者年龄预测(SAP):预测说话者的年龄段,如儿童、成人、老年人。
-
语音到文本聊天(STTC):将语音转换为书面语,并生成相应的文本回复。
OSUM技术原理
-
模型架构:
-
语音编码器:使用Whisper-Medium模型,包含2个一维卷积层和24个Transformer层,用于提取语音特征。
-
适配器:结合了3层1D卷积层和4层Transformer层,用于将语音编码器的输出与LLM的输入对齐。
-
语言模型(LLM):使用Qwen2-7B-Instruct模型,通过LoRA技术进行微调,支持多任务指令优化。
-
-
多任务训练策略:
-
ASR+X训练策略:在训练过程中同时优化ASR任务和目标任务(X),加速模态对齐,使LLM能够有效利用文本和声学模态。
-
两阶段训练:
-
第一阶段:在多任务数据集上微调Whisper模型。
-
第二阶段:将微调后的Whisper编码器与Qwen2 LLM集成,使用更大的数据集进行进一步训练。
-
-
-
数据处理流程:
-
ASR数据:使用公开的和内部的ASR数据集,总时长24,000小时。
-
其他任务数据:包括SRWT、VED、SER、SSR、SGC、SAP和STTC任务的数据,使用公开数据集和内部处理的数据,总时长50,500小时。
-
数据标注和增强:使用预训练模型和人工标注相结合的方法,确保高质量的训练数据。
-
-
训练设置:
-
硬件:第一阶段在8个Nvidia A6000 GPU上进行,第二阶段在24个华为Ascend NPU上进行。
-
学习率调整:使用warm-up调度器调整学习率,确保训练过程的稳定性和高效性。
-
OSUM应用场景
-
智能客服:通过语音情感识别(SER)和说话风格识别(SSR),智能客服系统可以更好地理解用户的情绪和意图,提供更贴心、更个性化的服务。
-
语音助手:在智能家居、智能车载等场景中,OSUM的语音识别(ASR)和语音到文本聊天(STTC)功能可以实现语音控制和自然语言交互,提升用户体验。
-
教育领域:在语言学习软件中,OSUM可以用于语音识别和情感分析,帮助学生纠正发音、评估口语表达能力,并提供情感反馈。
-
内容创作:在有声读物、播客等制作中,OSUM的说话风格识别(SSR)和语音情感识别(SER)可以帮助创作者优化内容,使其更具吸引力。
-
医疗健康:通过说话者年龄预测(SAP)和性别分类(SGC),OSUM可用于远程医疗中的语音健康监测,辅助医生评估患者状态。
-
情感分析与市场调研:在市场调研和社交媒体监测中,OSUM可以分析用户语音中的情感倾向,帮助企业更好地了解用户需求和市场反馈。
OSUM项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号