Migician简介
Migician是由北京交通大学、华中科技大学和清华大学联合开发团队提出的一种新型多模态大型语言模型(MLLM),专注于自由形式的多图像定位(Multi-Image Grounding, MIG)任务。该模型通过创新的两阶段训练方法和大规模的MGrounding-630k数据集,实现了在多幅图像中基于自由形式查询的精确定位能力,显著提升了模型在复杂多图像场景中的表现。开发团队还构建了MIG-Bench基准测试,用于全面评估多图像定位能力。Migician在多个任务中展现出卓越性能,超越了现有的最佳MLLMs,甚至在某些任务中超越了更大规模的模型。
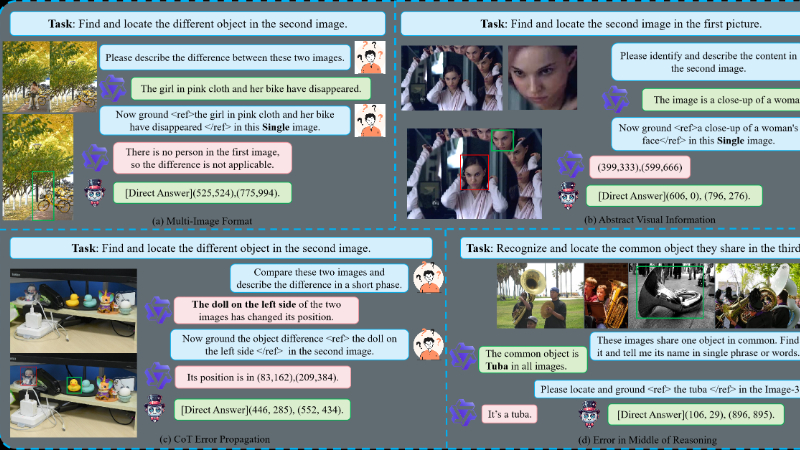
Migician主要功能
-
自由形式多图像定位(MIG):Migician能够在多幅图像中基于自由形式的查询(文本和/或图像)识别和定位相关的视觉区域。
-
跨图像理解:该模型不仅能处理单图像,还能在多个图像之间进行关联理解,适用于复杂的多图像场景。
-
高效推理:通过端到端的方式直接在多图像上进行定位,避免了传统多步骤推理方法的效率问题。
-
多任务处理:支持多种多图像任务,如差异检测、共同对象定位、对象跟踪等,适应灵活多样的应用场景。
Migician技术原理
-
Chain-of-Thought(CoT)框架:
-
分阶段推理:将MIG任务分解为两个阶段:首先利用多图像理解生成文本引用查询,然后通过单图像定位进行目标定位。
-
性能提升:尽管在简单场景中有效,但在处理抽象视觉语义时表现不稳定,且推理时间翻倍。
-
-
两阶段训练方法:
-
第一阶段训练:使用MGrounding-630k数据集中的MIG任务数据和一般任务数据增强模型的定位能力。
-
第二阶段训练:使用高质量的自由形式MIG指令数据进一步优化模型,使其适应更灵活多样的指令类型。
-
-
MGrounding-630k数据集:
-
数据来源:包含从现有数据集中派生的数据以及新生成的自由形式定位指令数据。
-
数据规模:包括63万条数据,涵盖多种多图像定位任务。
-
-
MIG-Bench基准测试:
-
任务多样性:包含10种不同任务、5900张多样化图像和超过4200个测试实例。
-
性能评估:用于全面评估模型在多图像定位任务中的表现,揭示现有模型与人类表现之间的差距。
-
-
模型融合技术:
-
权重平均:在第二阶段训练后,通过平均两个阶段训练得到的模型权重,平衡模型性能和灵活性。
-
Migician应用场景
-
自动驾驶:用于识别和定位道路环境中的关键目标,如车辆、行人和交通标志,提升车辆的环境感知能力。
-
监控系统:在监控视频中检测异常行为或目标,如识别入侵者或丢失物品,增强安防监控的智能化水平。
-
机器人导航与交互:帮助机器人在复杂环境中定位目标物体,实现精准的抓取或导航任务。
-
多媒体内容创作:在视频编辑或图像合成中,快速定位和替换特定视觉元素,提高创作效率。
-
智能教育:辅助教学场景,如在多张图片中定位和解释相关知识点,提升教学互动性和趣味性。
-
医疗影像分析:在多张医学影像中定位病变区域或对比不同影像中的关键特征,辅助医生进行诊断和分析。
Migician项目入口
- 项目主页:https://migician-vg.github.io/
- GitHub代码库:https://github.com/thunlp/Migician
- HuggingFace:https://huggingface.co/Michael4933/Migician
- arXiv技术论文:https://arxiv.org/pdf/2501.05767
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号