SigLIP 2:谷歌推出的多语言视觉-语言编码器
SigLIP 2简介
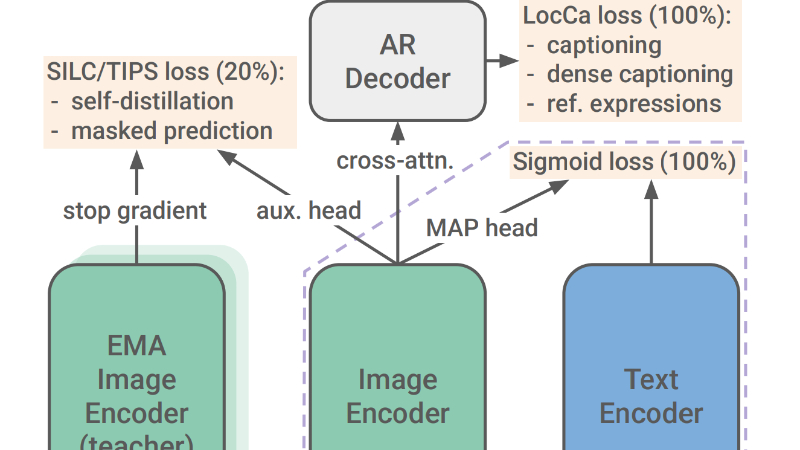
SigLIP 2是由Google DeepMind团队开发的一种新型多语言视觉-语言编码器。它在SigLIP的基础上进行了多项改进,通过结合基于标题的预训练、自监督损失(如自蒸馏和掩码预测)以及在线数据策划等技术,显著提升了模型在语义理解、定位和密集特征提取等任务上的性能。SigLIP 2支持多种分辨率和保留图像原始宽高比的NaFlex变体,能够更好地处理文档理解等对宽高比敏感的应用。此外,它还通过多语言数据训练和去偏技术,增强了模型在多语言任务中的表现,并提高了文化多样性和公平性。SigLIP 2在零样本分类、图像-文本检索、视觉问答等任务中均展现出卓越性能,为视觉-语言模型的多语言应用和密集预测任务提供了强大的支持。
SigLIP 2主要功能
-
多语言支持:SigLIP 2能够处理多种语言,提供强大的多语言视觉-语言编码能力,适用于不同语言和文化背景的任务。
-
零样本分类:无需特定任务的训练数据,SigLIP 2可以直接进行高精度的图像分类。
-
图像-文本检索:支持高效的文本到图像和图像到文本的检索,适用于多种应用场景。
-
密集特征提取:在语义分割、深度估计等密集预测任务中表现优异,能够生成高质量的密集特征。
-
定位任务:在指代表达理解和开放词汇检测等定位任务上表现出色。
-
多分辨率和宽高比支持:NaFlex变体支持多种分辨率和保留图像原始宽高比,适用于宽高比敏感的应用场景。
SigLIP 2技术原理
-
基于标题的预训练:结合LocCa技术,通过图像标题生成和指代表达理解预训练模型,提升OCR能力和定位任务性能。
-
自监督损失:引入自蒸馏和掩码预测技术,改善密集特征表示,使模型在密集预测任务中表现更佳。
-
数据策划:采用在线数据策划技术,优化训练数据的选择,提高模型的泛化能力和公平性。
-
多语言数据训练:使用包含多种语言的WebLI数据集进行训练,增强模型的多语言理解能力。
-
去偏技术:应用数据去偏技术,减少模型在性别、职业等方面的偏见,提升模型的公平性。
-
兼容性和扩展性:SigLIP 2设计为与SigLIP向后兼容,用户可以直接替换模型权重和多语言分词器,获得性能提升。
SigLIP 2应用场景
-
多语言图像分类:SigLIP 2能够支持多种语言的零样本分类任务,适用于跨语言的图像识别和分类。
-
图像-文本检索:可用于高效的文本到图像和图像到文本检索,广泛应用于搜索引擎和内容推荐系统。
-
视觉问答(VQA):结合语言模型,SigLIP 2可以处理视觉问答任务,为用户提供基于图像内容的自然语言回答。
-
文档理解:支持多分辨率和保留宽高比的特性,使其适用于文档图像处理,如OCR和文档内容理解。
-
开放词汇分割与检测:在语义分割和目标检测任务中,SigLIP 2能够处理未见过的类别,适用于动态环境下的视觉任务。
-
指代表达理解:在自然语言指导的图像定位任务中,SigLIP 2能够根据文本描述定位图像中的特定区域,适用于人机交互和智能导航。
SigLIP 2项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号