AgentRefine:北京邮电大学联合美团推出的新型智能体微调框架
AgentRefine 简介
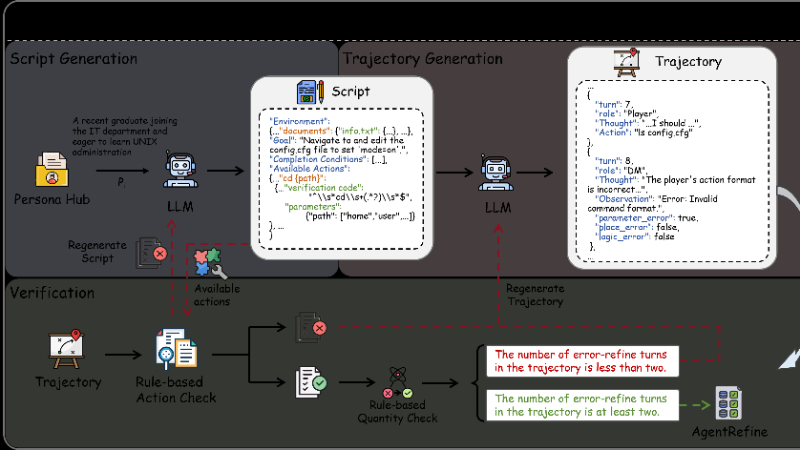
AgentRefine 是由北京邮电大学和美团联合开发的一种新型智能体微调框架,旨在通过自我修正机制提升基于大型语言模型(LLM)的智能体在多样化任务中的泛化能力。该框架通过合成多样化环境和任务数据,并引入错误修正步骤,使模型能够在交互中学习从错误中恢复并探索更合理的行动路径。实验表明,AgentRefine 在未见任务上的表现显著优于现有方法,展现出更强的鲁棒性和泛化能力。这一成果为智能体研究提供了新的范式,推动了开源 LLM 在复杂任务中的应用与发展。
AgentRefine 主要功能
-
提升智能体泛化能力:通过自我修正机制和多样化环境合成,AgentRefine 能够显著增强智能体在未见任务(held-out tasks)上的表现,使其在复杂多变的环境中更好地完成任务。
-
增强鲁棒性:AgentRefine 使智能体在面对环境扰动或任务描述变化时,仍能保持稳定的性能,避免因小的格式或逻辑变化而导致任务失败。
-
促进智能体的自我学习能力:通过在训练数据中引入错误修正步骤,AgentRefine 让智能体学会从错误中学习,避免重复错误行为,从而提升其在新环境中的适应能力。
-
生成多样化任务数据:通过合成多样化的人类角色(Persona)和环境,AgentRefine 能够生成涵盖多种场景和任务的智能体训练数据,防止模型过度拟合单一环境。
AgentRefine 技术原理
-
Agent 合成框架:
-
利用角色数据(Persona Hub)生成多样化的环境、任务和可用动作。
-
通过模拟“地下城主(DM)”和“玩家”的多轮交互,生成包含错误和修正步骤的训练轨迹。
-
-
自我修正机制:
-
在生成的轨迹中,通过验证器检测错误(如格式错误、逻辑错误)。
-
保留错误步骤并提示模型根据环境反馈进行修正,最终生成包含错误修正过程的训练数据。
-
-
Refinement Tuning(修正微调):
-
将生成的轨迹数据转换为特定格式,用于训练智能体。
-
修改损失函数,仅对正确动作计算损失,避免模型学习错误的推理过程。
-
-
多样化环境与任务生成:
-
通过合成多种环境和任务,防止模型过度拟合单一场景。
-
利用角色数据生成多样化任务,提升模型在新环境中的适应性。
-
-
强化交互学习:
-
通过模拟多轮交互,使模型在虚拟环境中不断学习和修正错误。
-
强调模型在交互中利用短期记忆修正历史决策错误的能力。
-
AgentRefine 应用场景
-
智能客服与客户支持:通过自我修正和泛化能力,AgentRefine 可以更灵活地处理客户咨询,适应不同客户的问题风格和复杂场景,提升客户满意度。
-
自动化办公助手:在处理文件编辑、任务规划等办公场景中,AgentRefine 能够根据反馈调整操作策略,避免重复错误,提高工作效率。
-
教育辅导系统:为学生提供个性化的学习指导,AgentRefine 可以根据学生的学习进度和反馈调整教学内容和方法,适应不同学习风格。
-
虚拟游戏与互动娱乐:在虚拟游戏环境中,AgentRefine 能够根据玩家行为和环境变化动态调整游戏策略,提供更具挑战性和趣味性的交互体验。
-
智能家居控制:通过自我修正机制,AgentRefine 可以更好地理解用户的指令意图,适应不同的家居设备和场景,提升用户体验。
-
医疗辅助系统:在医疗咨询和辅助诊断中,AgentRefine 能够根据患者反馈和医疗数据进行动态调整,提供更准确的建议和解决方案。
AgentRefine 项目入口
- 项目主页:https://agentrefine.github.io/
- Github代码库:https://github.com/Fu-Dayuan/AgentRefine
- arXiv技术论文:https://arxiv.org/pdf/2501.01702
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号